

Go, Vantage point
가까운 곳을 걷지 않고 서는 먼 곳을 갈 수 없다.
Github | https://github.com/overnew/
Blog | https://everenew.tistory.com/
티스토리 뷰
HSRP 실습하기

GNS3 구성
일단 모두 OSPF로 라우팅 경로를 전달하자.
지금 R1이 R5로 가는 길은 ISP1로 가게 되어, 하나로 수렴되어 보인다.
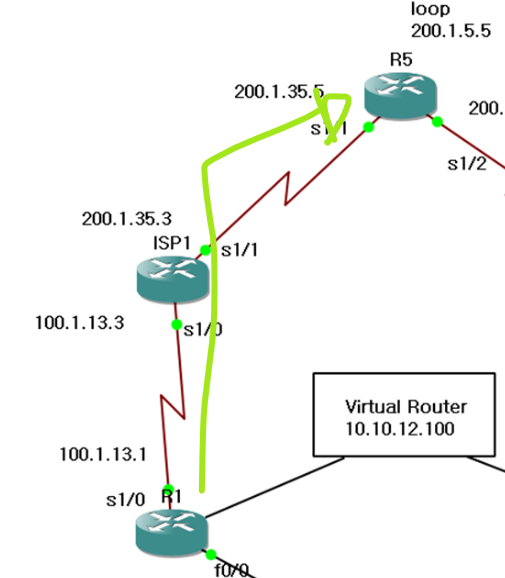
즉, 경로상으로 베스트 페스로 잡혀있음.
Client PC의 문제 상황
client인 PC는 GW를 하나만 가질 수 있다.
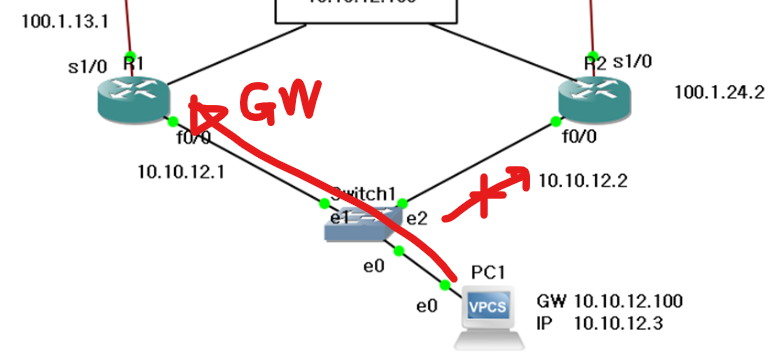
일단 PC의 GW를 R1으로 잡자.

가는 경로를 trace로 파악해 볼 수 있다.

경로를 파악해보면 베스트 path로 진행되고 있다.
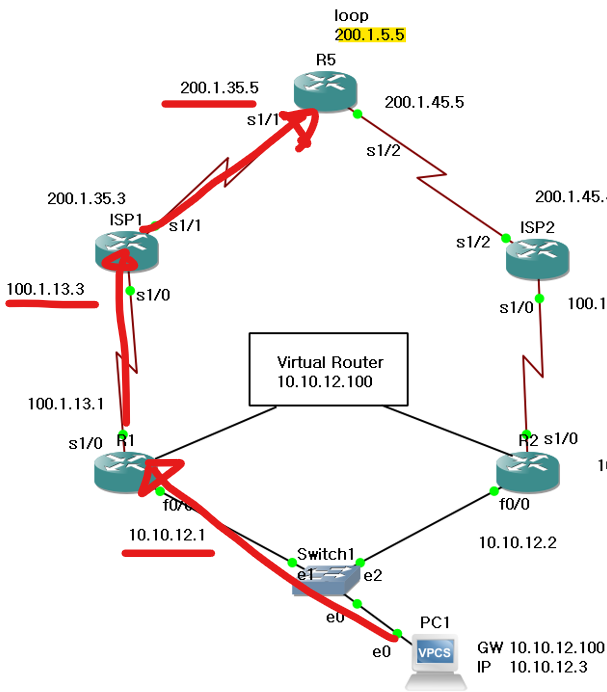
장애 강제 유발 시키기
지금은 PC의 게이트웨이(GW1)가 끊기면 통신 장애가 발생할까?
일단 R1 S1/0 인터페이스를 down 시켜도, OSPF에 의해 대체경로인 R2로 트래픽을 보내서 R5의 Loop back과 통신이 된다.

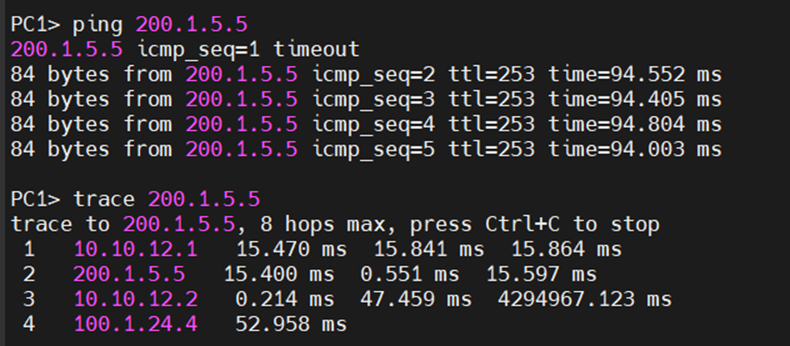
이는 라우팅의 동적 이중화였기 때문에 가능했다.
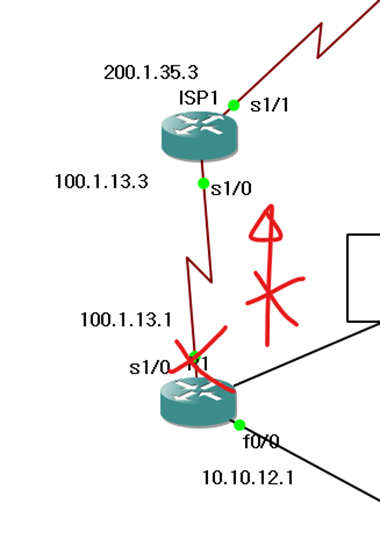
하지만 반대로 PC의 GW 역할을 하고 있는 f0/0을 끊으면 어떻게 될까?
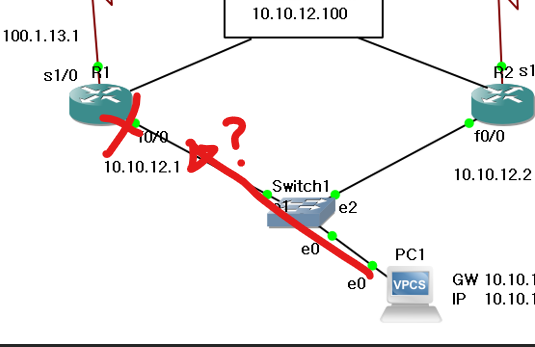

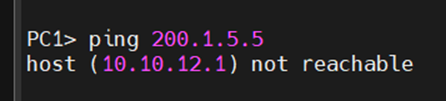
게이트웨이로 도달할 수 없다.
PC에서 GW를 수동으로 바꿀수 있기 한데, 인터넷이 문제가 생길 때마다, Client가 GW를 바꾸는 것은 말이 안 된다.
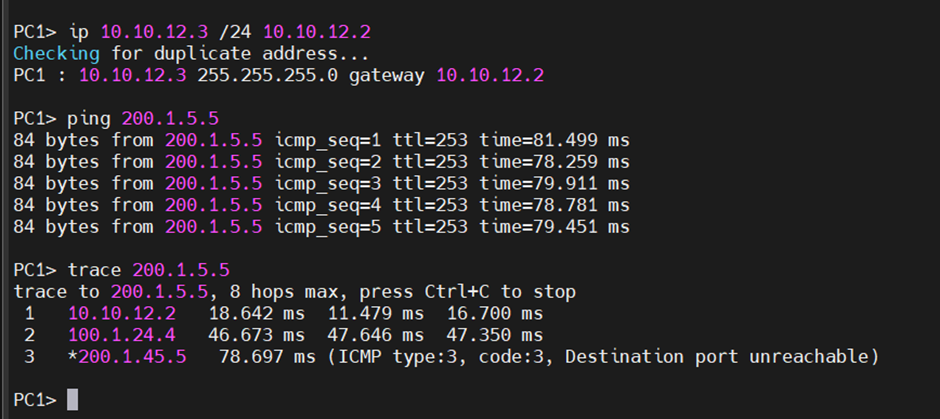
따라서 Client는 문제를 모르도록, 네트워크 내부에서는 게이트웨이만 살아 있으면 되고 외부에서는 경로를 살리면 된다.
이러한 문제를 해결하기 위해 게이트웨이의 이중화 프로토콜이 HSRP이다.
HSRP( Hot Standby Router Protocol )
이것은 네트워크에서 안정성과 가용성을 높이기 위해 사용되는 프로토콜이다.
HSRP는 여러 라우터 간에 논리적인 그룹을 형성하여, 이 그룹 내에서 하나의 활성 라우터와 여분의 대기 라우터를 관리한다.
그래서 만약 활성 라우터에 문제가 발생하면, 대기 라우터가 자동으로 활성 상태로 전환되어 네트워크의 연결을 유지한다.
이렇게 함으로써, HSRP는 네트워크의 신뢰성을 높이고 서비스 중단을 최소화하는 데 도움을 준다.
Router HSRP 세팅
인터페이스에 들어가서, standby 세팅.
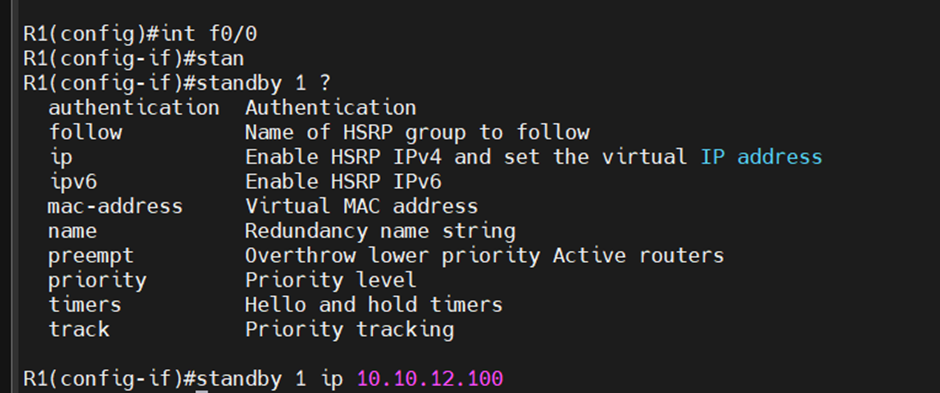
stanby 1 ip <virtual router ip>
R2 쪽에도 동일하게 같은 ip로 세팅해 준다.
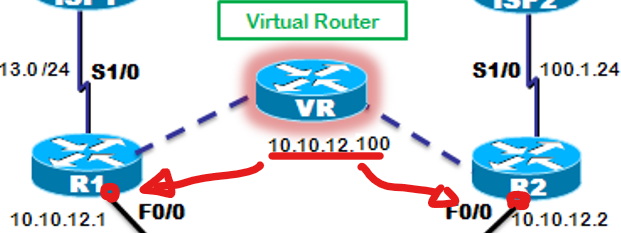
보통 Active로 선택되는 Router는 IP가 높은 것이다. (여기서는 R2가 높음)
지금은 stanby 설정을 천천히 했기 때문에, 선출 타임아웃이 되어 R1이 Active로 선출되었다.

R2는 스탠바이

각 라우터에 아래의 옵션을 넣어주면 ip가 높은 애가 active가 가져가게 된다.
standby 1 preempt
이제 Client PC의 GW를 우리가 준 Virtaul router ip로 바꾸게 되면,
트래픽이 active 쪽(R1)으로쪽(R1)으로 지나가게 된다.
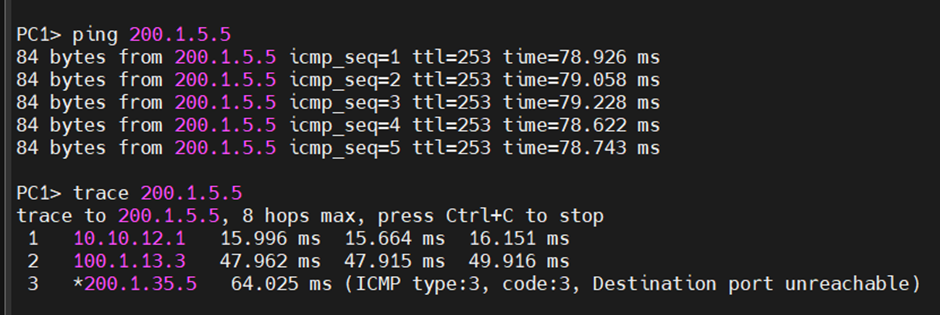
이제 R1의 f0/0에서 경로를 끊어보면 ative가 바뀌는 메시지가 출력된다.
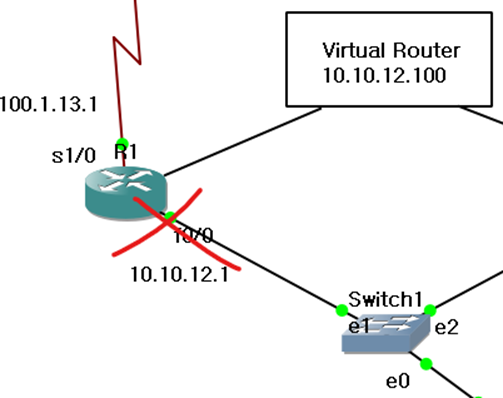

R2는 active로 바뀐다.

이제 R5로의 경로는 R2를 지나게 바뀐다.
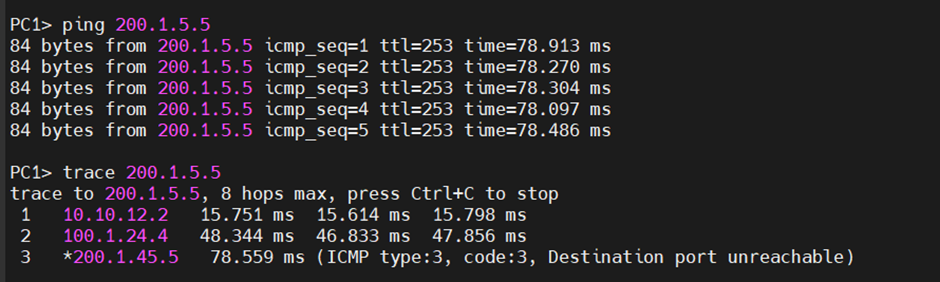
standby 1 preempt에 의해 R1의 경로를 복구해도 active는 R2가 가져간다.(IP가 높음.)

경로 비효율성 문제 해결(track, priority)
R2가 액티브인 상태에서 ISP로의 인터페이스 끊어보자.
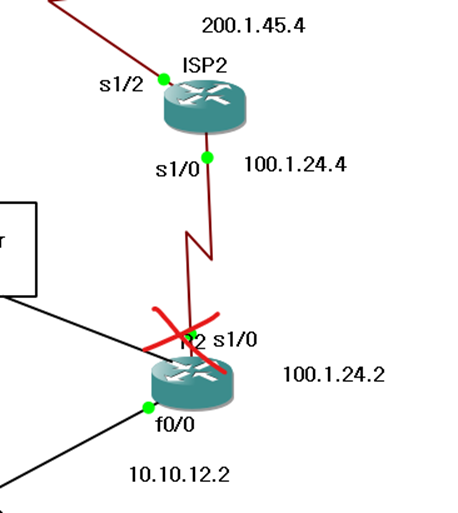
이러면 R2는 여전히 active 상태이지만, 최적 경로가 막혔으므로 R1으로 다시 트래픽을 보내게 된다.
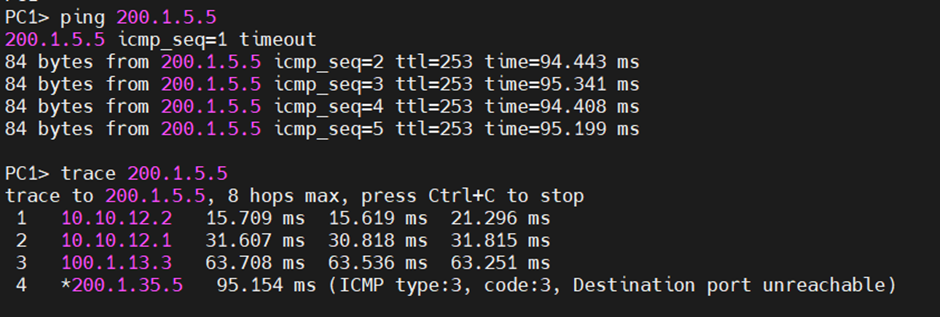
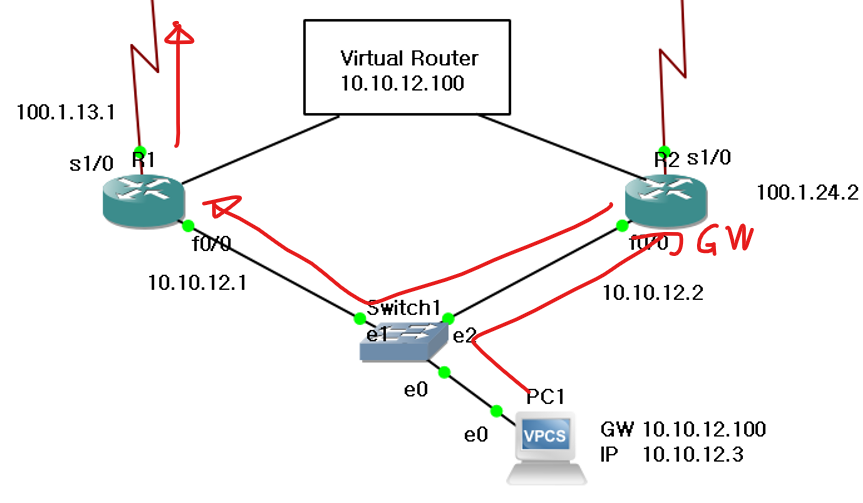
따라서 경로의 비효율성이 생긴다.
지금은 priority가 동일하니 priority를 바꾸어 해결해 보자.
(default priority = 100)
standby 1 priority 120으로 설정하면 100 이상이기 때문에 R1이 active가 된다.


standby track 명령어를 사용해서, track 하는 인터페이스에 장애가 발생 시 설정된 priority를 감소시킨다.
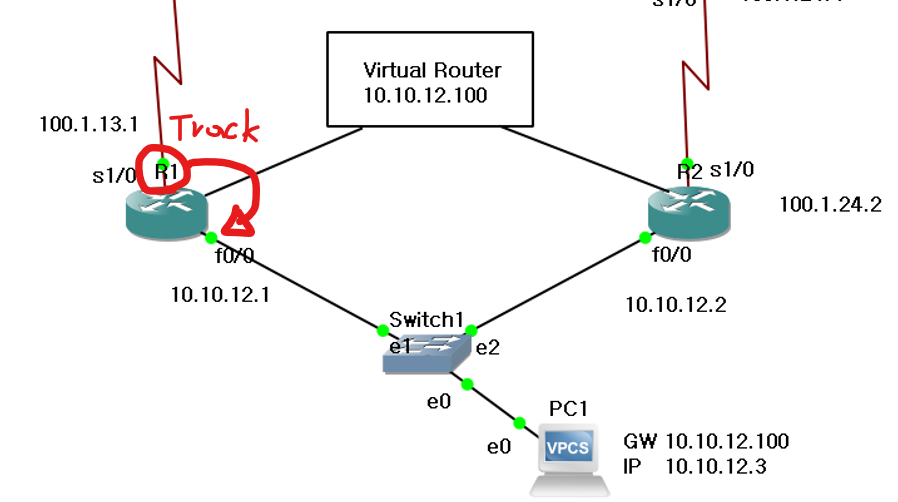
standby 1 track s1/0 30 #Track 하는 s1/0 interface문제 발생 시감소
이제 R1의 s1/0을 끊으면, priority 120에 -30이 적용되어 100보다 작은 90이 된다.

따라서 R2d(default priority 100)가 active가 된다.

이제 active가 바뀌면, Best 경로로만 나가게 된다.

단, tracking은 물리적으로 자신의 인터페이스만 가능하다.
따라서 목적지의 경로의 상태확인은 SLA로 하게 된다.
비정상일 때 어떠한 행동을 할지는 SLA는 무관 하므로 트리거로 삼아서 동작시킬 수 있음. Ex) aws Lambda
[GNS3] SLA & EEM으로 라우팅 경로 자동 복구 (for FTP, NTP, Log server)
[GNS3] SLA & EEM으로 라우팅 경로 자동 복구 (for FTP, NTP, Log server)
SLA(Service Level Agreement) 헬스 체크는 로컬 장비를 넘어갈 수 없다. ISP가 관리하는 저 너머는 장애가 나더라도 알 방도가 없다. 따라서 저 너머의 상태확인에는 추가적인 서비스가 필요하다. 이때
everenew.tistory.com
'CS > 네트워크 & Ubuntu' 카테고리의 다른 글
| OpenSSL을 활용한 인증서 구현하기(CA, HTTPS) (0) | 2024.02.27 |
|---|---|
| [Virtual Box] Ubuntu VM 디스크 용량 늘리기 (0) | 2024.02.23 |
| [GNS3] SLA & EEM으로 라우팅 경로 자동 복구 (for FTP, NTP, Log server) (0) | 2024.02.19 |
| 이중화 개념 & Layer2 경로 이중화(Spanning-Tree, STP, Raid STP) (0) | 2024.02.12 |
| [GNS3] 라우팅 경로 이중화 (AD, Metric, FTP, NTP) (0) | 2024.02.12 |