
Go, Vantage point
가까운 곳을 걷지 않고 서는 먼 곳을 갈 수 없다.
Github | https://github.com/overnew/
Blog | https://everenew.tistory.com/
티스토리 뷰
[GNS3] SLA & EEM으로 라우팅 경로 자동 복구 (for FTP, NTP, Log server)
EVEerNew 2024. 2. 19. 09:45
SLA(Service Level Agreement)
헬스 체크는 로컬 장비를 넘어갈 수 없다.

ISP가 관리하는 저 너머는 장애가 나더라도 알 방도가 없다.
따라서 저 너머의 상태확인에는 추가적인 서비스가 필요하다.
이때 사용하는 것이 SLA이다.
SLA란, Service Level Agreement의 약자로, 서비스 제공자와 이용자 간에 합의된 서비스 수준을 명시한 계약이다.
기본적으로 SLA는 서비스 제공자가 제공할 서비스의 품질과 성능에 관한 규정을 정의한다.
이를 통해 이용자는 서비스 제공자에게 기대하는 수준을 명확히 알 수 있으며, 서비스 제공자는 이에 부응하여 고객에게 신뢰성 있는 서비스를 제공할 수 있게 된다.
요약하자면, SLA는 서비스 제공자와 이용자 간의 합의된 서비스 수준을 정의한 계약이다.

SLA은 목적지로 정찰(프로브)을 보내서, 응답이 비정상일 때 대처한다.
보통 인프라의 안정성. 인터넷 품질을 체크할 때 SLA를 사용하게 된다.
하지만 SLA는 상태 체크만 해줄 뿐, 비정상 일 때의 대처는 해주지 않는다.
결국 SLA는 HSRP와 같이 대처 방안과 함께 사용되어야 있어야 의미가 있다.
우리는 HSRP가 아닌 EEM (Event Embedded Manage)를 통해 특정 이벤트 발생 시 특정 동작 실행하도록 설정해 줄 것이다.
EEM (Event Embedded Manage)
EEM (Event Embedded Manager)은 Cisco 장비에서 이벤트를 감지하고 이벤트에 대응하여 자동화된 동작을 수행하는 기능이다. 이것은 장비의 작동을 모니터링하고 필요한 조치를 취함으로써 네트워크의 안정성을 높이고 관리를 간소화하는 데 사용된다. EEM은 이벤트 기반 스크립팅을 지원하여 사용자가 원하는 동작을 정의하고 이벤트가 발생할 때 실행되도록 설정할 수 있다. 이를 통해 관리자는 장애 상황을 자동으로 처리하거나 보안 위협을 탐지하여 대응할 수 있다. 간단히 말하자면, EEM은 Cisco 장비에서 이벤트를 감지하고 이를 자동으로 처리하는 기능이다.
네트워크 환경 및 실습 목적

기존의 백업 경로는 링크가 down 됨을 인지하기까지 십 수초가 걸리기 때문에, 이중화는 진행했지만 가용성이 높다고 볼 수 없다.
따라서 우리는 R1에 설정된 R2로의 Best Path 장애 발생 시, SLA로 빠르게 감지하여 EEM을 통한 백업 경로로 전환해 주는 구성을 해줄 것이다.
GNS3 환경 구성
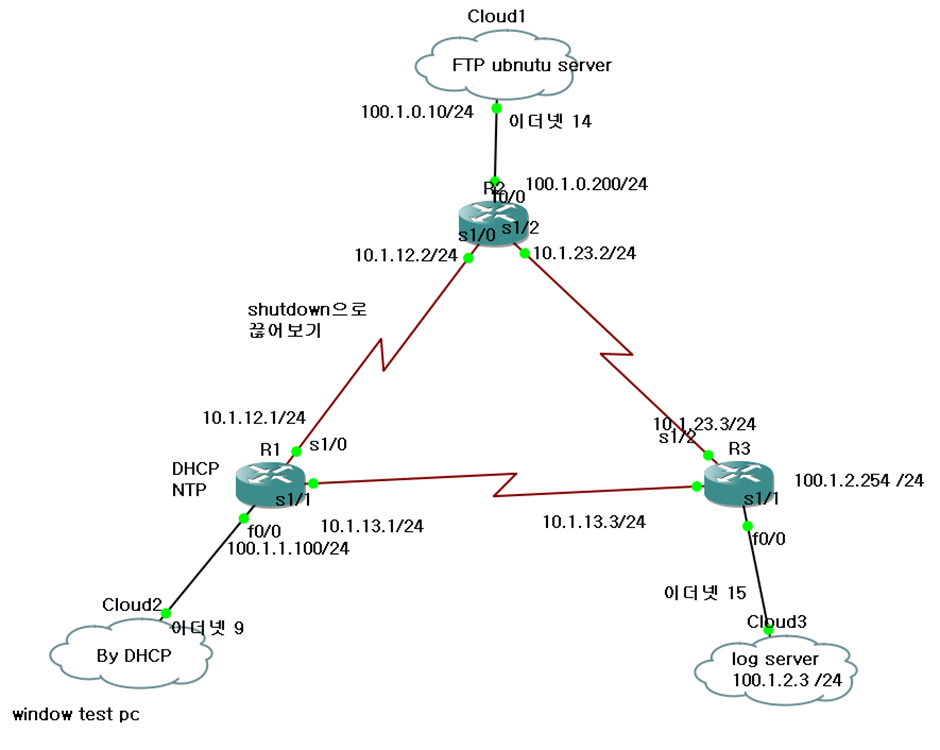
FTP 서버가 100.1.0.0/24.
R1 라우터가 DHCP와 NTP를 제공.
Shutdown으로 끊는 부분은 R1이 아닌 R2의 s1/0, ISP의 연결이 끊긴 느낌으로
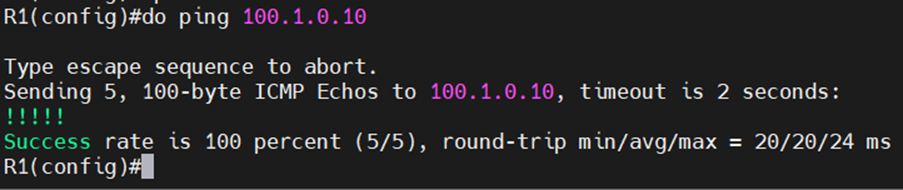
여기서 기존의 GNS 세팅을 그대로 사용해서 100.1.0.10인 FTP 서버를 대상으로 SLA를 진행하였는데,
R2의 S1/0인 10.1.12.2로 SLA를 하는 것이 정확한 세팅 법이니 참고하자.
(100.1.0.10인 FTP 서버는 경로가 잘 세팅되면 SLA의 ping에 대해 응답을 할 수 있어 R1-R2의 경로 오류에도 Health check가 정상이 될 수 있다.)
R1의 경로 우선순위
ip route 100.1.0.0 255.255.255.0 10.1.12.2 10 #R2로 바로
ip route 100.1.0.0 255.255.255.0 10.1.13.3 20 #R3 경유

현 상태에서는 Best path로 통신이 되는 상태
Best Path 장애 유발
R2쪽에서 R1으로의 링크를 차단한다.

차단하면 도달하지 않는다.

잠시 후 십 수초 정도 후에 링크가 down 된 것을 인식하여 routing 경로가 바뀐다.

100.1.0.0/24로의 트래픽이 10.1.13.3으로 가도록 바뀌어 있다.

다시 복구하면 잠시 후 up 상태로 바뀐다.

Router SLA 설정
ip sla 1
icmp-echo 100.1.0.10
timeout 800 #ms단위의 icmp timeout
frequency 1 # icmp timeout 이상으로 설정한, icmp 송신 주기
ip sla schedule 1 life forever start-time now #1번 sla를 바로 종료 없이 스케쥴
do show ip sla statistics 1로 확인해 보면,
Health check가 ok인 것이 확인된다.

패킷 확인 시 설정한 5초(이후 1초로 변경)마다 ping 이 진행된다.

Router FTP 설정
archive를 이용하여 정기적으로 Config Backup 하기
Router(config) ip ftp username <사용자명>
Router(config) ip ftp password <비밀 번호>
Router(config) archive
Router(config-archive) path ftp://<ftp서버ip>/R1-TEST
Router(config-archive) write-memory
Router(config-archive) time-period 1440 #스케줄 백업이 필요하다면 1440분(하루) 이후 백업


이는 best path로 진행되고 있다.
EEM으로 백업 경로 자동 설정
EEM 세팅
event manager applet LINK_DOWN # eem 이름을 LINK_DOWN
event track 10 state down # state down을 track
action 1 syslog msg "Internal Link Fail" # log 남기기
action 2 cli command "enable"
action 3 cli command "conf t"
action 4 cli command "no ip route 100.1.0.0 255.255.255.0 10.1.12.2" #best path 삭제
action 5 cli command "exit"
action 6 cli command "archive config" # 백업 경로로 conf 파일 백업
event manager applet LINK_UP
event track 10 state up
action 1 syslog msg "Internal Link Success"
action 2 cli command "enable"
action 3 cli command "conf t"
action 4 cli command "ip route 100.1.0.0 255.255.255.0 10.1.12.2 10" # best path 복구
track 10 rtr 1 reachability #SLA 1번과 EEM 10번 연결
Best Path 차단
이제 R2에서 끊으면

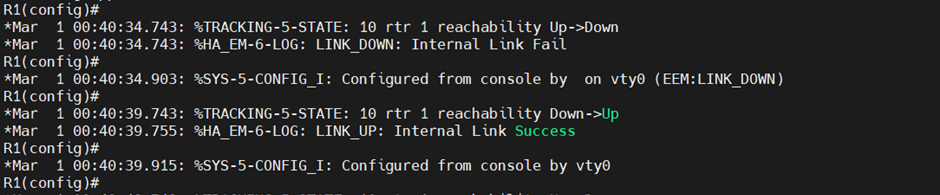
자동으로 세팅해 둔 EEM LINK_DOWN 스크립트가 실행된다.
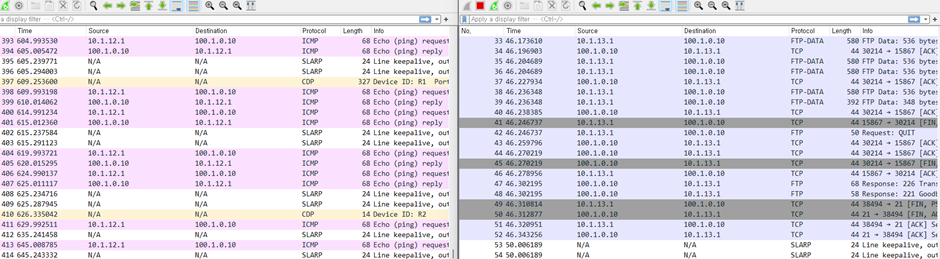
ICMP 응답이 안 오자 백업 경로를 활성화시켜 백업 FTP를 보내는 것이 확인된다
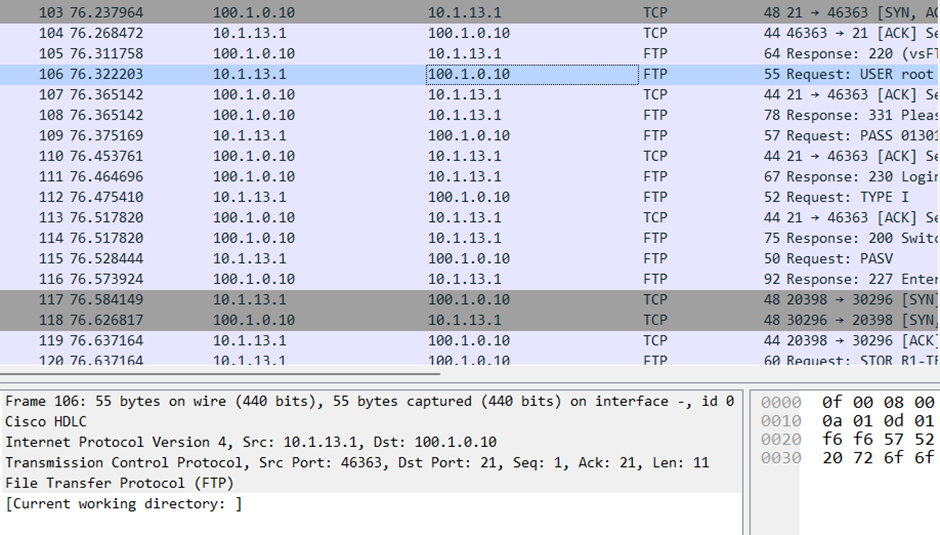

Best Path 복구
다시 r2에서 복구시키면 자동으로 Link-up 실행

라우팅 경로 자동 복구
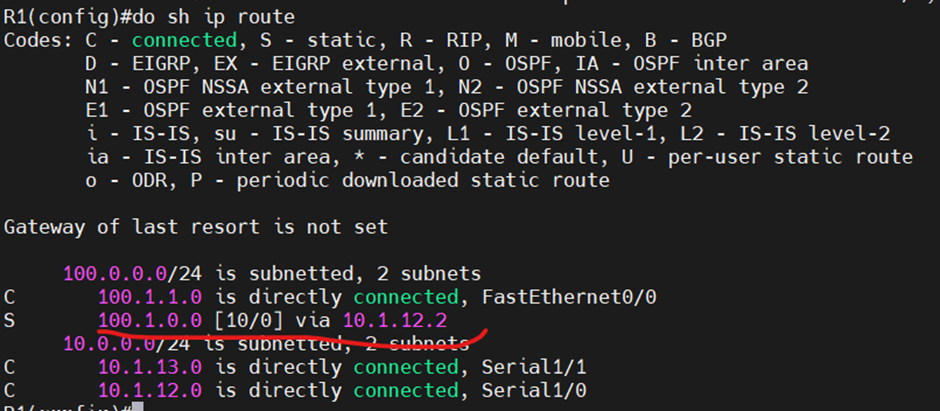
더 나은 복구 전략 모색하기
장애 발생 시 정책을 세팅하는 데 있어서, 얼마나 빠르게 복 시킬 수 있는지가 관건이라 할 수 있다.
만약 R1 자신의 인터페이스에 장애 발생 시, SLA로 Health check(빨라도 1초)를 하지 않더라도 바로 인지할 수 있을 것이다. 따라서 Health check로 문제 발생을 파악하기보다 빠르게 EEM으로 대처할 수 있다.
예시로 다음과 같이 인터페이스 down 로그를 패턴으로 백업 경로를 만들어 줄 수 있다.
event manager applet interface_down
event syslog pattern "%LINEPROTO-5-UPDOWN: Line protocol on Interface Serial1/0, changed state to down"
action 1 …
EEM에서 사용자 Input 사용하기
우리가 사용한 archive는 미리 세팅해 둔 ftp 값을 사용하기 때문에 입력을 받을 필요가 없지만, 이런 세팅이 없는 경우 FTP 커맨드를 통해 input을 넣어주어야 한다.
event manager applet backupR1
event track 2 state down maxrun 1000
action 1.0 cli command "enable”
action 1.1 cli command "copy run ftp:" pattern “remote host"
action 1.2 cli command "10.10.10.2" pattern "filename"
action 1.3 cli command "backupline1.cfg"
action 1.4 cli command "end”
이처럼 pattern을 사용해서 입력해 줄 수 있다.
혹은 redirect를 사용하면 사용자 입력 없이 진행할 수 있다.

Router DHCP 세팅
ip dhcp pool babo
network 100.1.1.0 255.255.255.0
default-router 100.1.1.100
option 42 ip 10.1.13.1 #ntp server
세팅 후, 같은 회선으로 연결된 window 10에 ipconfig/renew로 ip를 받아오자.
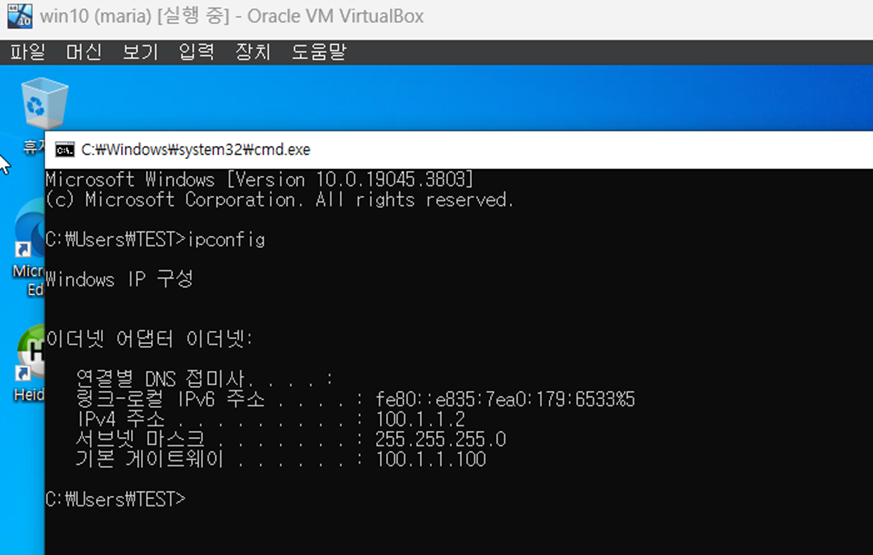
Router Ntp 설정

나머지 라우터는 ntp server 10.1.13.1 세팅

로그 수집 서버 만들기
apt install rsyslog
보통 ubuntu server는 기본 설치 되어 있다.
다른 서버로부터 받아오기 위해 주석 해제.
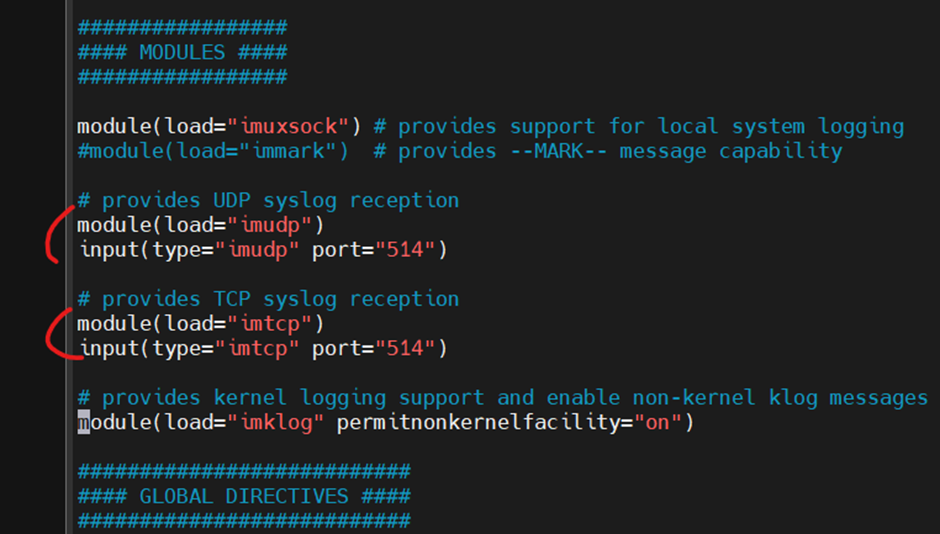
보통 로그는 UDP를 많이 사용한다고 한다.
UDP의 장점
- 간단하고 빠른 속도: UDP는 TCP와 달리 연결 설정이나 연결 유지 등의 오버헤드가 없기 때문에 빠른 데이터 전송이 가능합니다. 이는 로그 전송에 있어서 빠른 속도가 필요한 경우에 유용합니다.
- 작은 패킷 크기: UDP 헤더가 TCP 헤더보다 작기 때문에 UDP 패킷은 더 작습니다. 작은 패킷 크기는 네트워크 대역폭을 절약하고 데이터 전송 시에 더 효율적으로 이용할 수 있습니다.
- 다수의 로그 전송: UDP는 일반적으로 TCP보다 더 많은 수의 요청을 처리할 수 있습니다. 따라서 많은 양의 로그를 처리하고 전송해야 하는 경우에는 UDP가 유리할 수 있습니다
- 정리하면 로그가 많이 전송될 수 있으므로 손실을 감수하고 UDP를 사용하여 트래픽을 줄인다.
외부에서도 로그를 수집할 수 있도록 설정해 주자.
sudo nano /etc/rsyslog.d/10-remote.conf
해당 설정파일에 아래를 삽입해 자동으로 변수로 경로 만들어주기.
$template RemoteLogs,"/var/log/remote/%HOSTNAME%/%PROGRAMNAME%.log"
*.* ?RemoteLogs
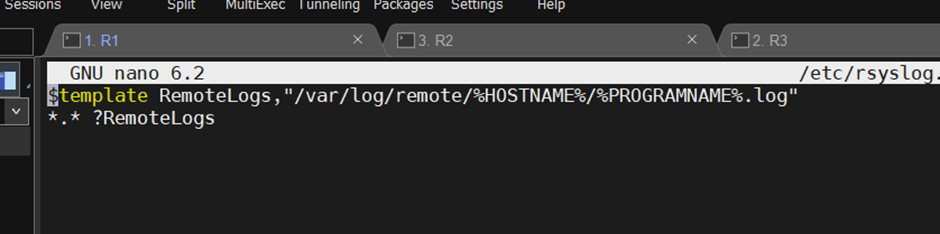
이 설정은 다른 서버에서 수신된 로그를 /var/log/remote 디렉터리에 저장하도록 한다.
sudo systemctl restart rsyslog # 재시작
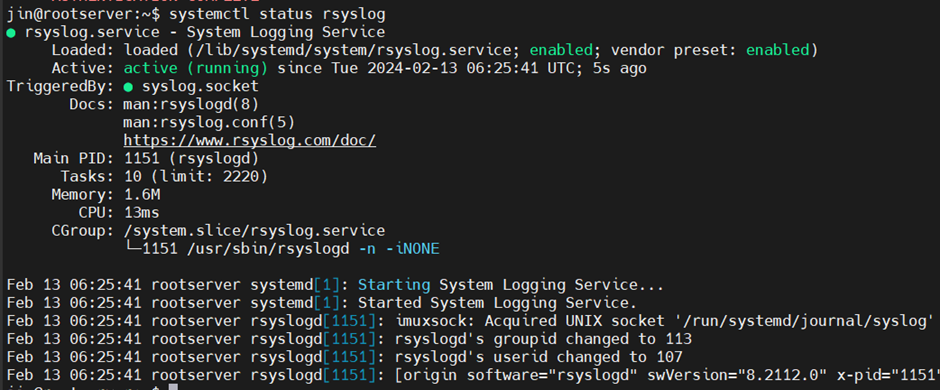
문제 시 514 port 확인하자. (방화벽 해제)
Ubnutu 서버에서 로그 서버로 전송
이제 Ubnutu 서버에서 로그 서버로 자신의 로그를 보내는 세팅을 진행한다.
sudo nano /etc/rsyslog.conf
이 설정파일에 *.* @rsyslog-server-ip-address:514 를 집어넣는다.
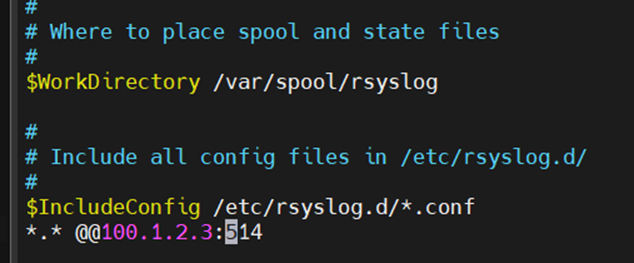
@@두 개면 tcp를 의미한다.
Tcp는 신뢰적인 데이터 전송이 있지만, 세션 연결을 위해 많은 cost가 소비될 수 있다.
sudo systemctl restart rsyslog #재시작
이제 /var/log/remote 폴더에 자신과 ns1(ftp서버의 폴더가 생성되어 있다.)


들어가 보면 Ns1서버의 log가 생성되어 있다.

다른 서버의 로그를 확인해 볼 수 있다.


확인해 보면 log가 이동 중이다.

라우터에서 로그 서버로
logging 100.1.2.3 #로그서버 ip
logging trap informational
logging trap <severity-level>
여기서 <severity-level>은 로그의 심각도 수준을 나타낸다. 예를 들어, logging trap informational은 정보 수준부터 모든 로그를 전송한다.
로그 레벨, severity-level
Cisco 라우터의 로그 레벨(Severity Level)은 다음과 같이 정의됩니다. 이러한 레벨은 로그의 중요도나 심각성을 나타냅니다. 로그 레벨이 낮을수록 더 많은 로그가 기록됩니다.
- emergency (0): 시스템이 사용할 수 없을 정도로 심각한 문제가 발생했습니다. 일반적으로 이 레벨의 로그는 거의 사용되지 않습니다.
- alert (1): 시스템이 비정상적인 상태에 있으며 즉각적인 조치가 필요합니다.
- critical (2): 비상조치가 필요한 심각한 문제가 발생했습니다.
- error (3): 오류가 발생했으며 문제를 발생시켰지만 시스템은 계속해서 작동할 수 있습니다.
- warning (4): 잠재적인 문제가 발생했거나 잘못된 구성이 감지되었습니다.
- notification (5): 정상적인 운영 중에 발생한 중요한 이벤트입니다.
- informational (6): 정보를 제공하는 이벤트입니다.
- debugging (7): 디버깅에 유용한 정보를 제공하는 이벤트입니다.
일반적으로 로그 레벨을 설정할 때는 레벨에 따라 어떤 이벤트를 로깅할지 결정하게 됩니다. 예를 들어, logging trap warning을 설정하면 warning 레벨부터 emergency 레벨까지의 로그를 전송합니다. 설정에 따라 로그 레벨을 조정하여 로그를 보다 효과적으로 관리할 수 있습니다.


End로 conf t를 나가면 log가 전송되었다는 메시지가 뜬다.
Informational은 정보라면 모두 전송해 주기 때문에 이러한 간단한 조작에서 로그가 전송되었다.
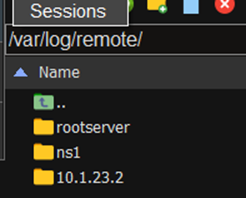
로그서버에서 라우터 폴더 (10.1.23.2)가 확인이 된다.

모든 로그는 로그 서버에 부하가 심하므로 원한다면 레벨 별로 세팅해서 보내 보자.
'CS > 네트워크 & Ubuntu' 카테고리의 다른 글
| [Virtual Box] Ubuntu VM 디스크 용량 늘리기 (0) | 2024.02.23 |
|---|---|
| [GNS3] HSRP로 라우터(GateWay) 이중화 (track, Priority) (0) | 2024.02.19 |
| 이중화 개념 & Layer2 경로 이중화(Spanning-Tree, STP, Raid STP) (0) | 2024.02.12 |
| [GNS3] 라우팅 경로 이중화 (AD, Metric, FTP, NTP) (0) | 2024.02.12 |
| [GNS3] 라우터 간의 IPSec VPN & Tunneling 적용하기 (1) | 2024.02.12 |