
Go, Vantage point
가까운 곳을 걷지 않고 서는 먼 곳을 갈 수 없다.
Github | https://github.com/overnew/
Blog | https://everenew.tistory.com/
티스토리 뷰
AWS Lambda란?
AWS Lambda는 AWS의 클라우드 Serverless 서비스이다.
서버리스(serverless)란 개발자가 서버를 관리할 필요 없이 애플리케이션을 빌드하고 실행할 수 있도록 하는 클라우드 네이티브 개발 모델입니다.
서버리스는 서버가 없다기보다는 추상화를 통해 신경 쓸 필요가 없어지는 것이다.
서버는 AWS가 관리하여 탄력적으로 스케일 업/다운이 진행된다.
특히, 트리거를 통해 실행되기 때문에 실행된 만큼만 비용을 지불하면 된다.
만약 대학교의 홈페이지 공지가 올라오는 것을 이벤트라고 하면, 이를 트리거로 등록하여 크롤링을 진행하여 slack 봇으로 메시지를 전달하는 lambda 코드를 작성해 보자.
AWS Lambda로 학교 공지사항 크롤링하기
일단 Lambda 함수를 생성해주자.

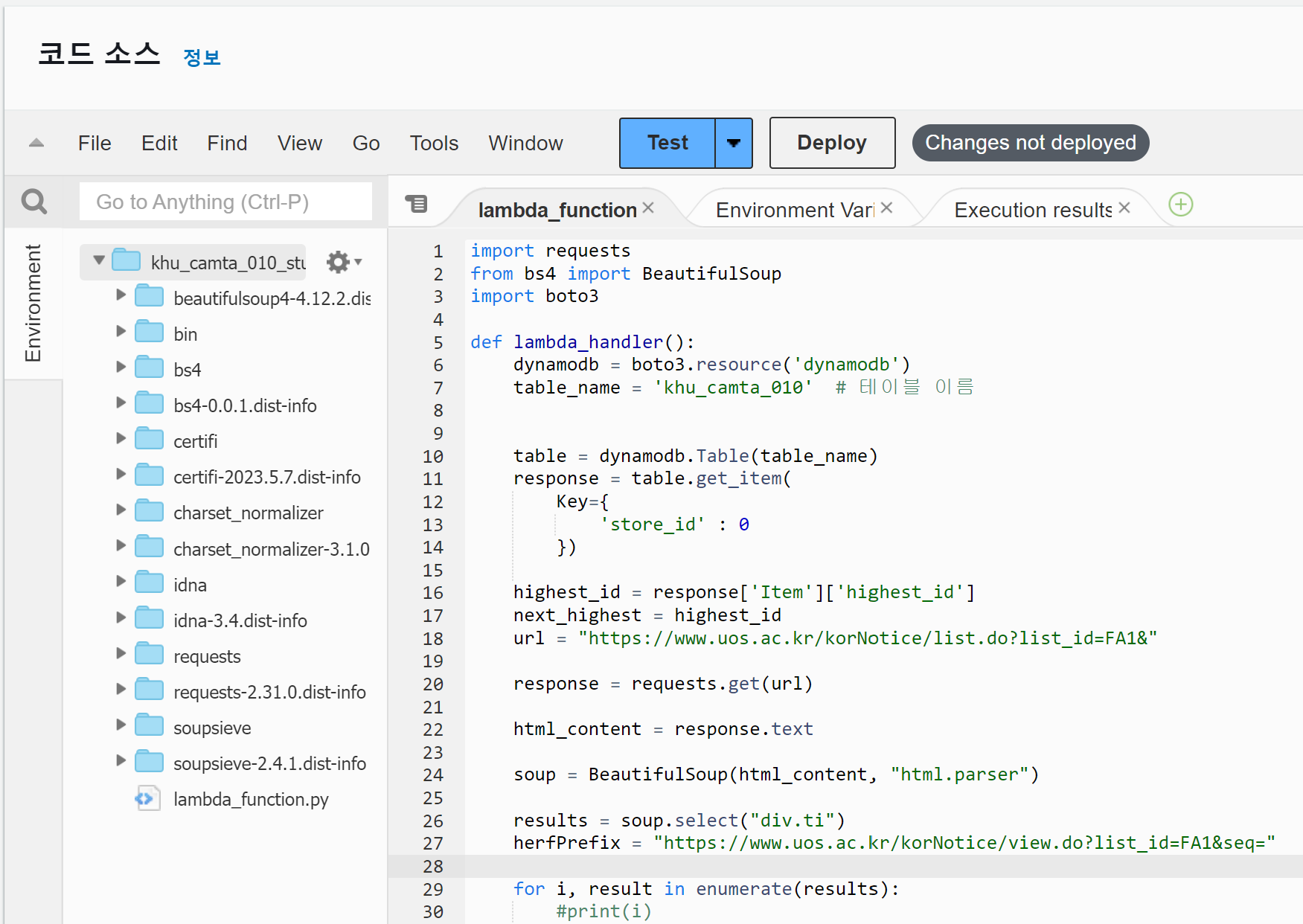
크롤링하는 코드를 작성하고 테스트를 눌러서 이벤트를 생성해 주자.
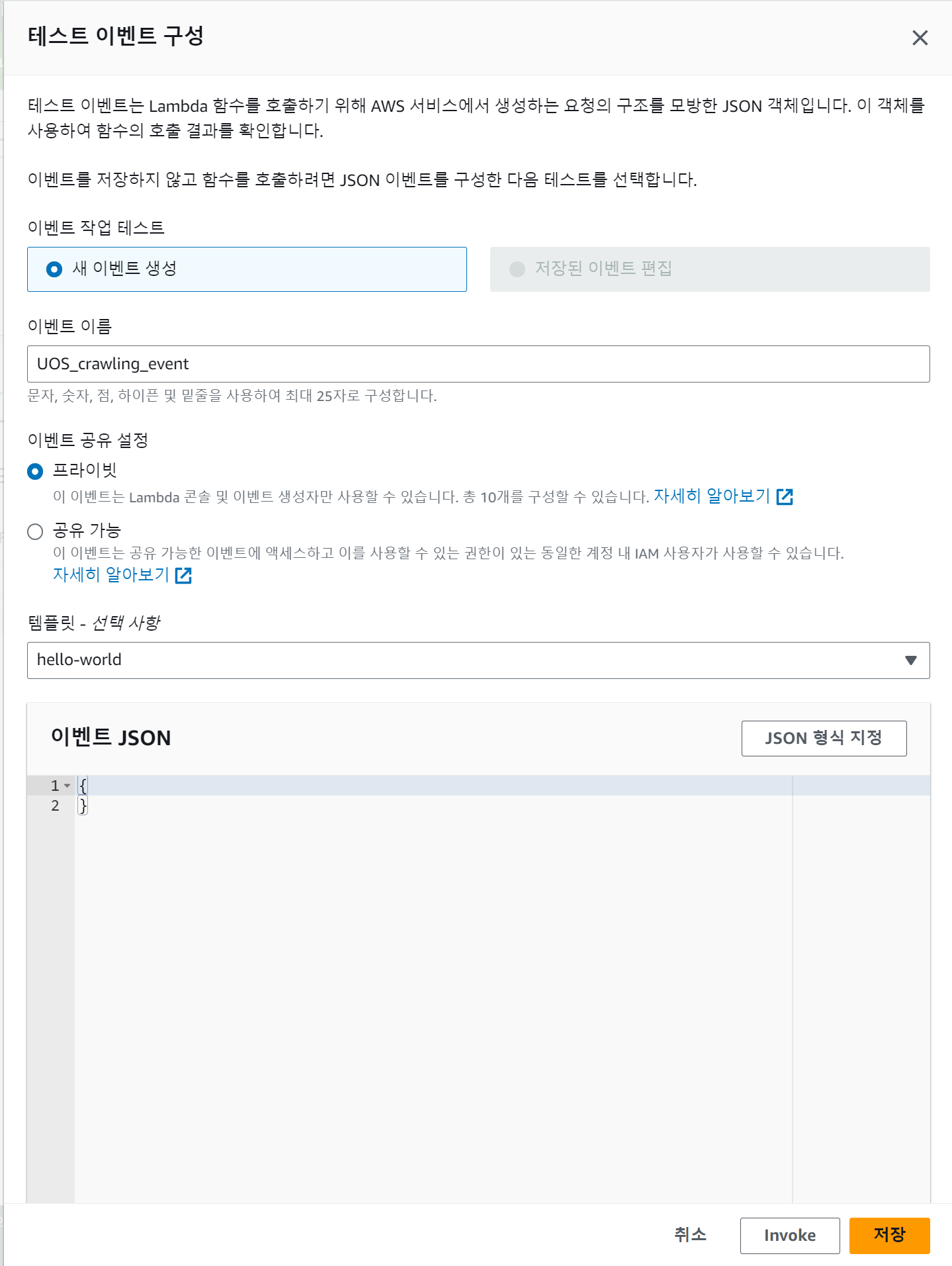
문제는 lambda는 서버리스로 동작하기 때문에 크롤링한 데이터가 새로운 공지사항인지 알 수가 없다.
본인의 학교 공지사항 html 코드를 분석해 본 결과, 새로운 공지사항이면 이전 공지 사항들보다 post의 id(숫자)가 높다.
따라서 lambda에 전역 변수로 크롤링한 공지사항 중에 가장 높은 post id 유지할 수 있다면, 새로 크롤링한 데이터가 새로 등록된 것인지 알 수 있을 것이다.
하지만, lambda에서 전역 변수를 설정할 수 있을까?
여러 문서를 찾아보았지만, 힘들 것으로 파악되었다.
따라서 AWS의 DynamoDB를 사용하여 공지사항의 제목과 링크, 현재 크롤링한 데이터중 가장 높은 post id를 저장시키는 코드를 작성하자.
import requests
from bs4 import BeautifulSoup
import boto3
import requests
def lambda_handler(event, context):
hookurl = "웹후크 url"
dynamodb = boto3.resource('dynamodb')
table_name = '테이블 이름' # 테이블 이름
table = dynamodb.Table(table_name)
response = table.get_item(
Key={
'store_id' : 0
})
highest_id = response['Item']['highest_id']
next_highest = highest_id
url = "https://www.uos.ac.kr/korNotice/list.do?list_id=FA1&"
response = requests.get(url)
html_content = response.text
soup = BeautifulSoup(html_content, "html.parser")
results = soup.select("div.ti")
herfPrefix = "https://www.uos.ac.kr/korNotice/view.do?list_id=FA1&seq="
for i, result in enumerate(results):
#print(i)
title = result.select_one("a").text.strip()
fnView = result.select_one('a')['href']
datas = fnView.split(',');
post_id =int( datas[1].split('\'')[1]);
if(post_id > highest_id ):
continue
herf =herfPrefix+ str(post_id)
payload = { "text" : title+ " "+ url }
requests.post(hookurl, json=payload)
# DynamoDB에 데이터 삽입
table = dynamodb.Table(table_name)
table.put_item(
Item={
'store_id': i + 1,
'title': title,
'url': herf,
'post_id': post_id
}
)
if(post_id >next_highest):
next_highest = post_id
if(next_highest != highest_id):
table.update_item(
Key={
'store_id' : 0
},
UpdateExpression='SET highest_id = :val1',
ExpressionAttributeValues={
':val1': next_highest
}
)
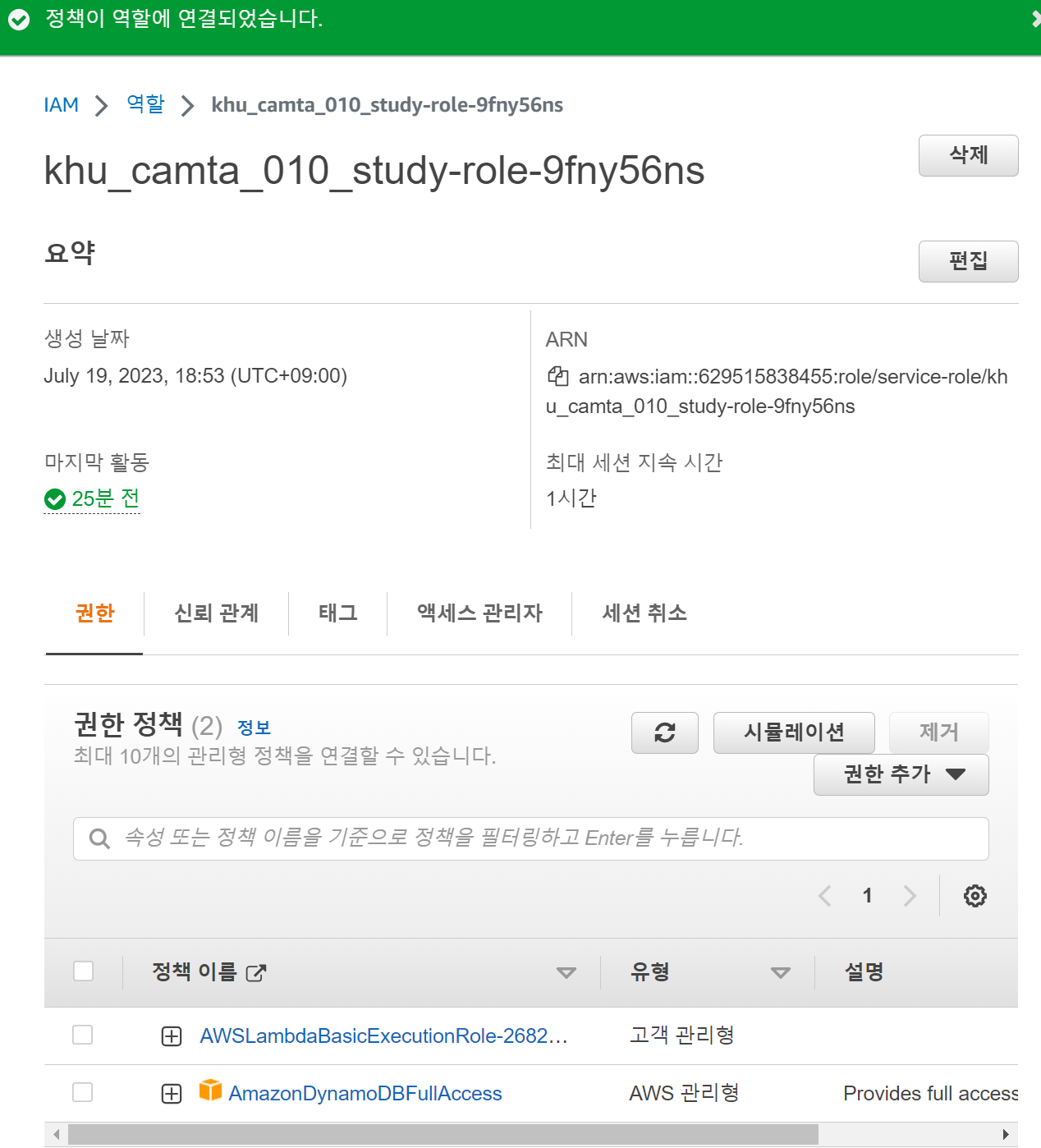
이때 코드를 실행하면 오류가 발생하는데, 이는 lambda 함수가 DB에 접근 권한이 없기 때문이다.
AWS의 IAM의 역할에서 자신의 lambda role를 찾아서 정책 연결을 해주자.

데이터를 삽입해야 하므로 AmazonDynamoDBFullAccess 권한을 추가해 주자.

이제 이 lambda 함수가 특정 주기로 실행되게 만들면 아래와 같이 DynamoDB에 데이터가 쌓이게 된다.

15분 단위로 크롤링을 해오기 위해 트리거를 추가해 주자.
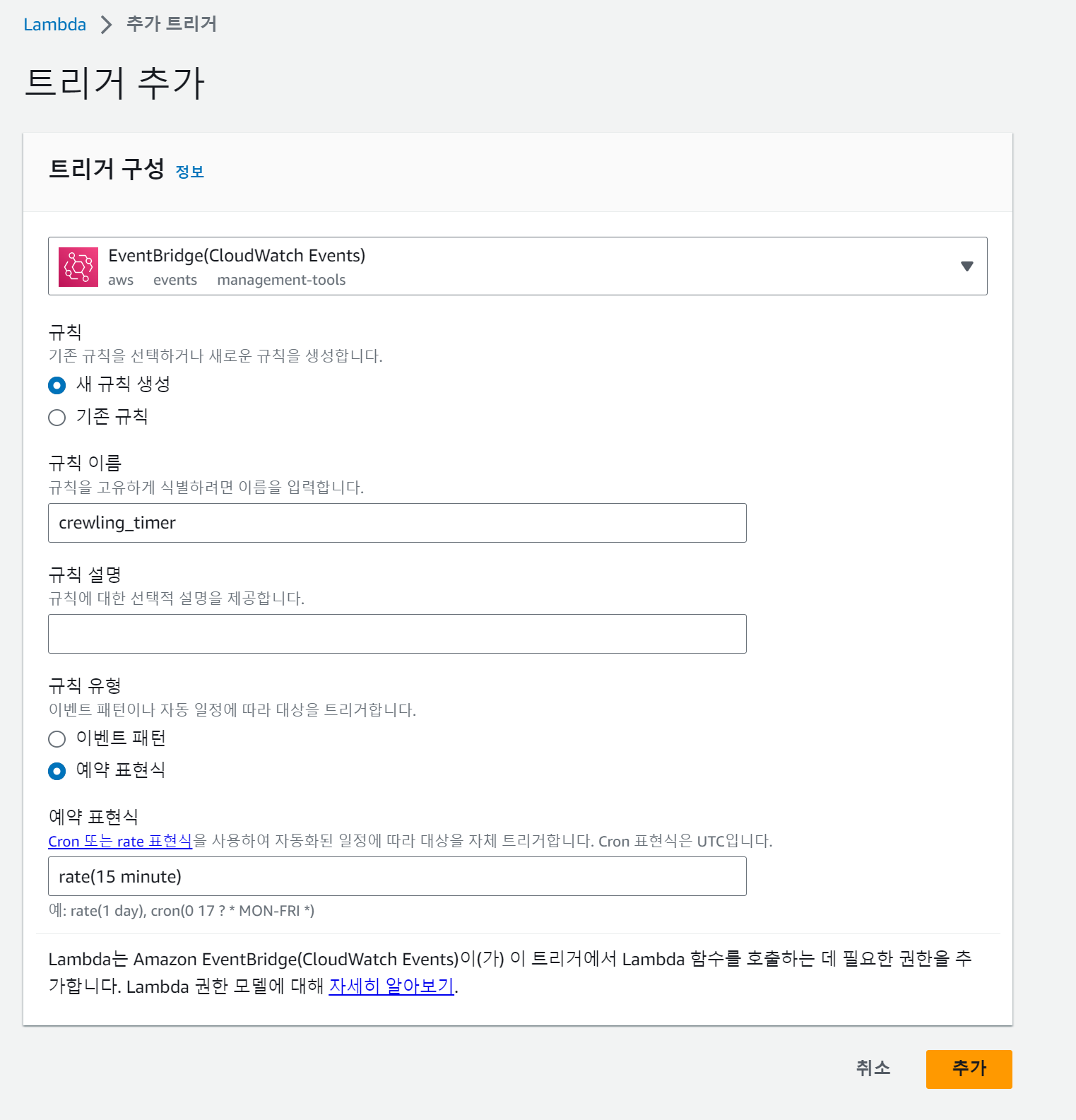
이제 15분 단위로 함수가 실행된다.

공지 알림 Slack Bot 만들기
이제 스크롤된 DynamoDB의 데이터를 사용하는 slack봇을 만들면 되는데,
가장 편한 방법은 WebHook를 통해 일방적으로 메시지를 슬랙 채널에 보내주는 방법이다.
직접 봇의 대화를 커스텀화 하려면 EC2로 따로 코드를 실행시켜 주어야 한다.
WebHook를 채널에 추가하는 자세한 방법은 아래 게시글을 참조하였다.
(완벽히 동일한 내용이니 이번 포스팅에는 생략하겠습니다.)
[Python] Slack WebHooks 을 통해 작업 진행상황 알림 받아보기! (feat. Incoming WebHooks)
최근에 크롤링을 하면서 네이버 뉴스의 기사를 크롤링하고 그 크롤링한 데이터를 MariaDB에 insert하는데 워낙 크롤링하는 데이터의 개수가 많다보니 time.sleep(0.5) 의 0.5초 시간까지 더하여 24시간 ~
somjang.tistory.com
이제 webhook의 url만 있다면 lambda 함수에서도 바로 슬랙 메시지 request를 보낼 수 있다.
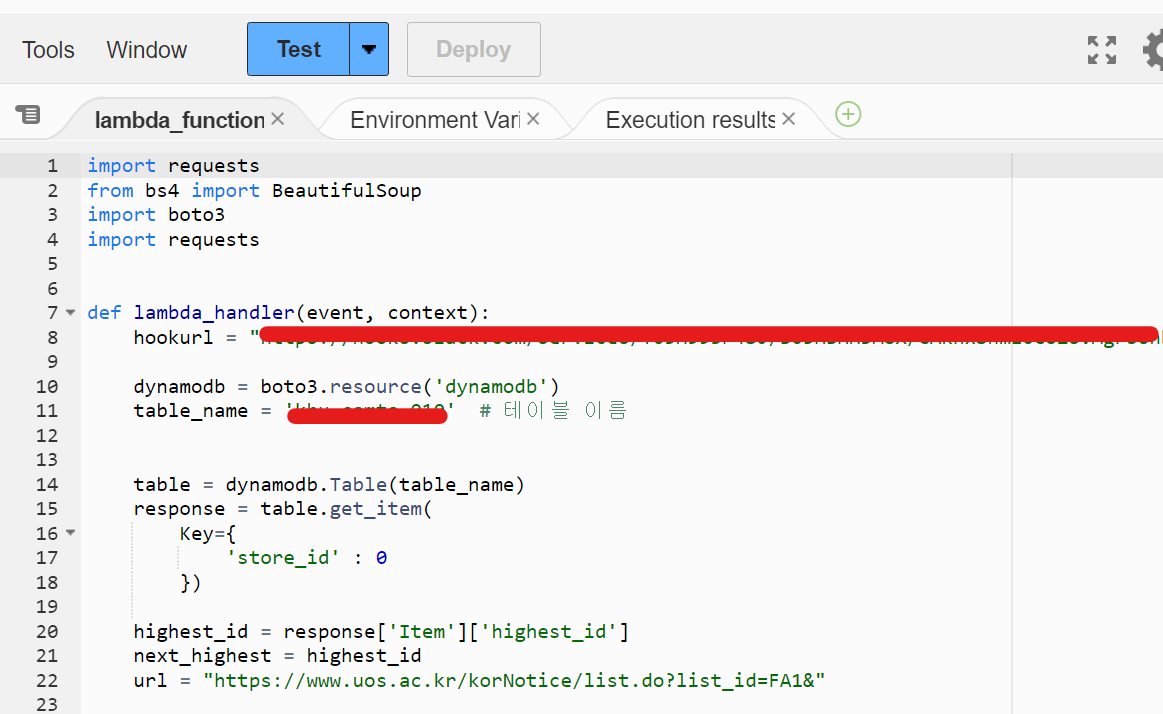
작성한 lambda Deploy를 하면 트리거에 의해 15분 단위로 실행되고, 새로운 공지사항이 있다면 webhook를 통해 슬랙 메시지를 보내준다.

구현에 있어서 DB에 공지의 title과 url을 저장시켰는데, 사실 최근 post_id 변수 하나만 따로 저장할 수 있다면 DB 없이도 lambda 만으로 구현할 수 있다.
또는 DB에 데이터를 더 자세히 적재하여, 공지 유형 별로 안내해 주는 봇을 만들 수도 있을 것이다.
하지만 AWS Lambda 기능은 비싸므로, 배포는 힘들 것 같다;;
람다의 단점으로는 함수 실행의 준비까지 cold start의 문제, 15분 이하의 실행시간만 제공, 변수와 메모리 제한 등의 문제가 있다.
Serverless는 분명 매력적인 서비스이지만, 제한 사항이 많기 때문에 목적에 맞게 잘 사용해야 하는 것이지 은탄환이 될 수는 없다.
Lambda의 동시성 문제나 전역변수에 대해서 궁금하다면 아래 게시글을 참조해 보자.
https://blog.hoseung.me/2022-02-27-lambda-global-variables/
AWS Lambda의 동작 원리 - 전역 변수가 유지될까?
간단한 질문으로부터 시작된 AWS Lambda 파헤치기
blog.hoseung.me
'Cloud > AWS' 카테고리의 다른 글
| AWS Lambda로 Slack에 메시지 전송하기 (SNS 트리거) (0) | 2023.10.12 |
|---|---|
| AWS boto3로 SNS Topic에 메시지 전송하기 (python) (0) | 2023.10.10 |
| ECS 태스크 실행 오류 (ECR pull error) (0) | 2023.09.19 |
| AWS Solutions Architect Associate (SAA - C03) 대학생 합격 후기 (3) | 2023.09.19 |
| EC2에 간단한 Streamlit 웹 서비스 올리기 (+ 동시성) (0) | 2023.07.20 |