
Go, Vantage point
가까운 곳을 걷지 않고 서는 먼 곳을 갈 수 없다.
Github | https://github.com/overnew/
Blog | https://everenew.tistory.com/
티스토리 뷰
*주의: Transformer와 Attention 내용이 혼합되어 있습니다.*
이전 글: Seq2Seq 정리
GitHub - bentrevett/pytorch-seq2seq: Tutorials on implementing a few sequence-to-sequence (seq2seq) models with PyTorch and Torc
Tutorials on implementing a few sequence-to-sequence (seq2seq) models with PyTorch and TorchText. - GitHub - bentrevett/pytorch-seq2seq: Tutorials on implementing a few sequence-to-sequence (seq2se...
github.com
논문: https://arxiv.org/abs/1706.03762
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org
Attention은 convolutional layer를 사용하지 않고, linear한 attention mechanisms과 normalization을 이용한다.

BERT(Bidirectional Encoder Representations from Transformers)는 가장 유명한 Transformer의 변형이다.
특히, BERT의 pre-trained 버전은 embedding layer를 대체하는데 사용되고 있다.
이 Colab 코드의 preparing data 부분은 이전 글인 seq2seq와 동일하다.
따라서 Model을 확인해 보자.
Encoder
ConvSeq2Seq와 비슷하게 Transformer의 encoder는 모든 source 문장을 압축하려 하지 않는다.
문장 X의 여러 단어들을 하나의 context vector로 만들기 보다는 context vector들의 sequence로 만들었다.


따라서 더 이상 time step에 따른 hidden state가 존재하지 않는다.
하지만, 각 context vector는
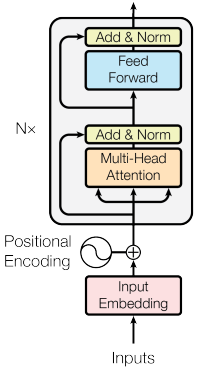
우선, 토큰들은 모두 standard embedding layer를 통과한다.
이 모델은 recurrent가 없기 때문에, 문장에서의 토큰 순서도 상관이 없다.
기존에는 어순 정보가 필요했기 때문에 순서에 따라 학습이 진행되었다.
따라서 속도가 굉장히 느렸는데, 순서가 상관이 없어지면서 parallel 하게 처리가 가능해졌다.
단, 어순 정보가 추가적으로 필요하다. 따라서 second embedding layer인 positional embedding layar가 필요하다.
이 어순 정보는 positional encoding에 담기는데, 이는 각 token의 token embedding과 더해진다.
따라서 같은 token라도 다른 위치에 있다면 embedding값이 약간씩 달라지게 된다.
더하는 과정에서는 token embedding에 hidden dimension size 값의 root를 곱해주어 normalization 해준다.

(단, 실제 논문에서는 positional embedding을 사용하지 않고 fixed static embedding을 사용한다.)
이제 N개의 encoder layer를 거치면 decoder에서 사용할 vectors Z를 얻을 수 있다.
그렇다면 그 encoder layer는 어떤것 일까?
Encoder Layer
일단 source 문장을 encoder layer를 통과시키고 그것을 multi-head attention layer로 mask 한다.
그 후에 Layer Normalization layer를 통과 시키고 position-wise feedforward layer도 통과시킨다.
이 과정의 결과가 다음 layer의 input이 되어 반복된다.
단, layer 간의 parameter는 독립적으로 학습된다.
Multi head attention layer는 encoder layer 로서 사용된다.
여기서는 다른 문장이 아닌 자기 자신을 대상으로 attention이 적용되기 때문에 self attention이라고 부른다.
Multi Head Attention Layer

Attention은 queries, keys and values로 생각될 수 있다.
query는 key와 함께 사용되어, 가중치를 나타내는 attention vector를 얻는다.
attention vector는 softmax의 결과로 모든 값의 합이 0이 되는 0~1 사이의 값을 가진다.
standard dot product은 아래와 같이 간단히 수행된다.
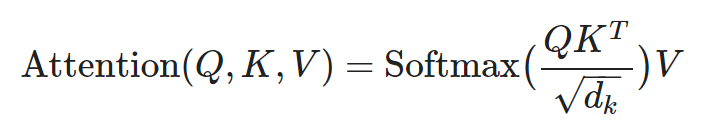
그리고 d(k)(head dimention, 아래에서 자세히 설명)로 scaling 한 값에 softmax를 수행하고, value(V)를 곱해준 값이다.
standard dot product에 d(k)가 적용되는 이유는 값이 너무 커지지 않도록 normalization 하는 것이 성능에도 효과적이기 때문이다.
Transformer는 scaled dot-product attention이 사용되어, query와 key가 내적으로 결합된다.
하지만 scaled dot-product attention에서는 간단히 query, key와 value가 간다히 적용되진 않는다.
single attention application가 진행되는 것이 아니라, query, key와 value가 여러 개의 heads들로 나뉘어 parallel 하게 계산이 진행된다.

W(O)는 Multi head attention layer가 진행된 이후에 적용되는 linear layer이다.아래의 function들 또한 linear layer들이다.

MultiHead는 attention을 여러 번 적용한 값을 사용하므로 single attention을 적용한 것보다 더 정확한 score가 계산될 수 있다.
Position-wise Feedforward Layer
그림에서도 main block으로 표현된 Position-wise Feedforward Layer는 사실 논문에서도 왜 사용하는지 설명하지 않는다.
내부적으로는 ReLU와 Drop out을 적용시킨다.
Decoder
decoder의 목적은 encoder의 source representation vectors Z를 받아 target sentence를 예측하는 것이다.
예측 값과 실제 값의 차이는 model parameter 학습에 사용된다.

decoder에는 multi-head attention이 두 가지가 존재한다.
'CS > GNN' 카테고리의 다른 글
| cuDNN란? (ROCm, HIP API) (0) | 2025.03.10 |
|---|---|
| [논문 리뷰] Light Graph Convolutional Collaborative FilteringWith Multi-Aspect Information (0) | 2023.03.08 |
| Seq2Seq 간단 정리 (0) | 2023.02.23 |
| [논문 리뷰] LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation (0) | 2023.01.05 |
| [GNN] Graph Neural Network - 2 (0) | 2023.01.04 |