
Go, Vantage point
가까운 곳을 걷지 않고 서는 먼 곳을 갈 수 없다.
Github | https://github.com/overnew/
Blog | https://everenew.tistory.com/
티스토리 뷰
원문: https://github.com/bentrevett/pytorch-seq2seq
GitHub - bentrevett/pytorch-seq2seq: Tutorials on implementing a few sequence-to-sequence (seq2seq) models with PyTorch and Torc
Tutorials on implementing a few sequence-to-sequence (seq2seq) models with PyTorch and TorchText. - GitHub - bentrevett/pytorch-seq2seq: Tutorials on implementing a few sequence-to-sequence (seq2se...
github.com
논문: https://arxiv.org/abs/1409.3215
Sequence to Sequence Learning with Neural Networks
Deep Neural Networks (DNNs) are powerful models that have achieved excellent performance on difficult learning tasks. Although DNNs work well whenever large labeled training sets are available, they cannot be used to map sequences to sequences. In this pap
arxiv.org
Seq2seq의 가장 흔한 모델은 encoder-decoder이다. 이는 RNN에서 input을 singel vector화 하기 위해 사용된다.
이 singel vector를 context vector라고 하자.
이 context vector는 전체 input 문장을 추상화로 표현해 준다.
이 vector가 두 번째 RNN에서 decode되는데, target(out)을 문장을 word 하나하나 생성해 준다.
이제 번역 과정을 그린 예시를 확인해 보자.

input 문장은 "guten morgen" 노란색의 embedding layer를 통과하여 초록색의 encoder의 input으로 들어간다.
<sos>는 start of sentence, <eos>는 end of sentence를 의미하는 토큰이다.
x를 문장의 각 단어라고 하자.

encoder RNN은 각각의 time step(t)마다, h(t)라는 hidden state를 out으로 출력한다.

e는 embedding layer를 의미하므로, e(x(t))는 단어 x(t)의 embedding 된 값이다.
이 hidden state가 문장을 vector화로 표현한 값이 된다.
이러한 RNN 구조는 LSTM이나 GRU(Gated Reccurent Unit)와 같은 recurrent architecture에서 사용될 수 있다.
위의 그림에서 가장 초기의 h(0)은 zeros 혹은 학습된 파라미터를 사용한다.
문장의 마지막 단어인 x(T)가 RNN을 통과하면 최종적인 hidden state, h(T)를 얻을 수 있고, 이것이 context vector가 된다.
context vector를 지금부터 빨간색인 z라고 표현하자.
이제 파란색인 decoder RNN에 "good morning" 문장을 넣어 decode 해보자.
이번에는 embedding layer을 d, hidden state를 s로 표현하였다.

여기서 s(0)은 우리가 구한 z가 된다.
embedding layer인 d의 경우 표현이 다르듯이, 다른 parametter로 구성된 다른 layer를 의미한다.
이제, hidden state인 s들을 실제 word(y로 표현)로 변환해야 한다.
이를 위해 사용하는 것이 보라색 linear layer이다.

model을 train 할 때는 얼마나 많은 단어를 맞추는 가를 평가하여, 단어 생성을 중단시킬 수 있다.
예측된 문장이 아래와 같을 때

실제 문장과 비교하여 loss를 계산하고 파라미터를 update 해나간다.

원문을 확인해 보면 colab에서 직업 코드를 실행해 볼 수 있다.
일단 Data의 전처리 작업이 들어간다.
문장들을 dataset에서 받아오고, tokenizer를 통해 단어별로 토큰화 시켜준다.
이때 오히려 문장을 역순으로 만들어주면 효과적이었다는 논문의 내용을 토대로, 역순으로 만들어 준다.
SRC가 독일어, TRG가 target 영어 문장이 된다.
실제 상요하는 dataset에서는 30,000개의 서로 대응되는 영어, 독일어, 프랑스어 문장이 들어있고, 각 문장들은 12개 이하의 단어로 이루어져 있다.
source와 target이 되는 문장 중 하나를 출력해 보면, 역순으로 token화 돼있음을 확인할 수 있다.
src: ['.', 'büsche', 'vieler', 'nähe', 'der', 'in', 'freien', 'im', 'sind', 'männer', 'weiße', 'junge', 'zwei']
'trg': ['two', 'young', ', ', 'white', 'males', 'are', 'outside', 'near', 'many', 'bushes', '.']
학습 시에 적어도 두 번 이상 등장한 단어만을 사용하기 위해, 단 한번 등장한 단어는 <unk>(unknown)으로 바꾼다.
그 이유는 "information leakage"로 인한 영향을 막기 위해서 이다.
batch를 만들 때는 source의 문장 길이와 target의 문장 길이를 맞추기 위해 padding을 넣기도 한다.
이제 Seq2Seq model을 확인해 보자.
1. Encoder
논문에서는 4-layer LSTM으로 encoder를 구성하지만, 여기서는 2-layer로만 구성하여 설명한다.
multi-layer에서는 bottom layer의 hidden state가 그대로 upper layer의 input으로 들어가게 된다.
특히, LSTM의 경우 cell state(c)도 각 step마다 반환이 된다. 하지만 cell state는 이전 hidden state와 반영되지만, upper layer의 input으로 들어가진 않는다.

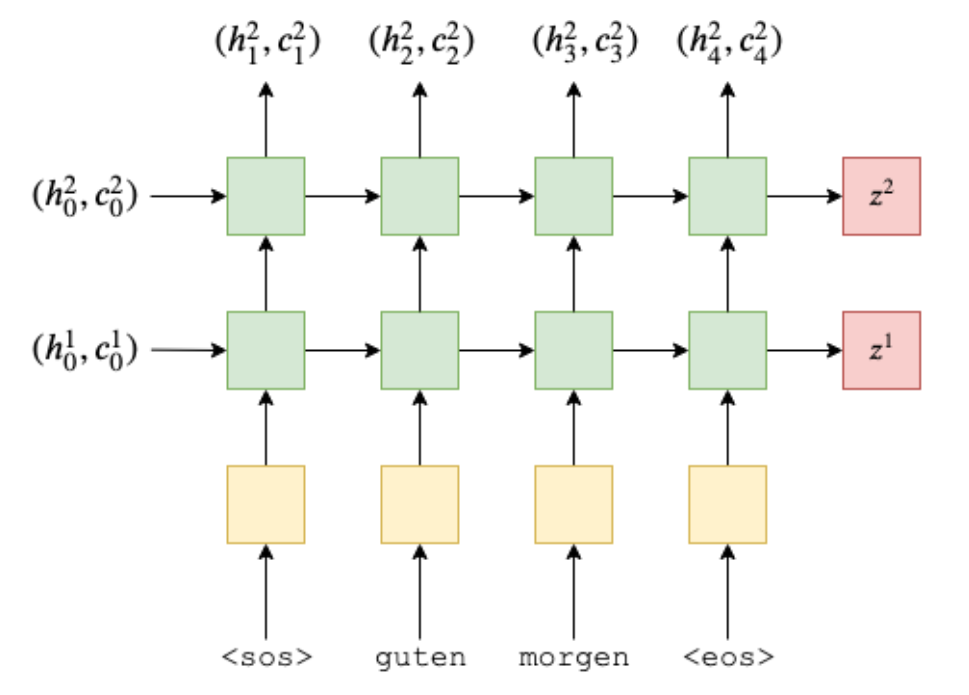
2. decoder
decoder도 multi-layer를 사용한다.

3. 최종 모델

'CS > GNN' 카테고리의 다른 글
| [논문 리뷰] Light Graph Convolutional Collaborative FilteringWith Multi-Aspect Information (0) | 2023.03.08 |
|---|---|
| Attention 간단 정리 (0) | 2023.02.23 |
| [논문 리뷰] LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation (0) | 2023.01.05 |
| [GNN] Graph Neural Network - 2 (0) | 2023.01.04 |
| [GNN] Graph Neural Networks - 1 (0) | 2023.01.03 |