
Go, Vantage point
가까운 곳을 걷지 않고 서는 먼 곳을 갈 수 없다.
Github | https://github.com/overnew/
Blog | https://everenew.tistory.com/
티스토리 뷰
파드의 상태(STATUS)
파드는 자신의 상태를 스스로 판단해서 모니터링에게 데이터 던져줄 수 있다.
• Pending: 포드를 생성하는 요청이API서버에의해승인됐지만, 어떠한 이유로인해아직 실제로 생성되지 않은 상태입니다.
예를 들어, 포드가 아직 노드에 스케줄링되지 않았을 때는 포드의 상태가 Pending으로 출력됩니다.
• Running: 포드에 포함된 컨테이너들이 모두 생성돼 포드가 정상적으로 실행된 상태입니다.
일반적으로 쿠버네티스에서 바람직한 상태(Desired)로 간주하는 포드의 상태
• Completed: 포드가 정상적으로 실행돼 종료됐 음을 의미합니다.
포드 컨테이너의 init 프로세스가 종료코드로서0을 반환한 경우에 해당
• Error: 포드가 정상적으로 실행되지 않은 상태로 종료됐 음을 의미합니다.
포드 컨테이너의 init 프로세스가0이 아닌 종료 코드를 반환했을 때에 해당
• Terminating: 포드가 삭제 또는 퇴거(Eviction)되기 위해 삭제 상태에 머물러 있는 경우
Completed vs Error
컨테이너 내부의 프로세스도 종료될 때 종료 코드를 반환하는데, 컨테이너의 init 프로세스가 어떠한 값을 반환 하느냐에 따라 포드의 상태가Completed또는 Error로 설정

항상 재시작으로 주면, 다시 running이된다.
프로드(Probe)
각 파드의 상태를 (정찰하여) 관리 유지한다.
liveness Probe
컨테이너 내부의애플리케이션이 살아있는지(liveness) 검사합니다.
• 검사에 실패할 경우 해당컨테이너는 restartPolicy에 따라서 재시작 됩니다.
• 실제 애플리케이션이 제대로 동작하는지 직접 확인.
readiness Probe
컨테이너내부의 애플리케이션이 사용자요청을 처리할 준비가 됐는지(readiness) 검사합니다.
• 검사에 실패할 경우 컨테이너는 서비스의 라우팅 대상에서 제외됩니다. 즉 트래픽을 받을 수 없게한다.
• 정상 서비스들만 연결시켜주고, 문제아들은 차단한다.
Startup Probe
부하가 큰 컨테이너는 시작 시 오랜 시간이 걸리며 이때 liveness & readiness probe에 의해종료 및 실패가 될 수 있습니다. 이러한 동작을 방지하기 위해 사용됩니다.
• 처음 애플리케이션기동을 Startup probe에의해서 점검(최초 1회 성공) OK되면, 그 이후 readiness & liveness probe가 동작.
postStart: 파드의 컨테이너가 실행되거나 삭제될 때, 특정 작업을 수행하도록 라이프사이클 혹(Hook)을 YAML에 정의
preStop: 파드가 종료될 때, 특정작업을 수행하도록 라이프사이클 혹(Hook)을 YAML에 정의
상태 검사방법 3가지
HttpGet
HTTP요청을 전송해 상태를 검사합니다. HTTP요청의 종료 코드가200또는 300번 계열이 아닌 경우 애플리케이션의 상태 검사가 실패한 것으로 간주합니다.
• 요청을 보낼 포트와 경로, 헤더, HTTPS사용 여부 등을 추가로 지정 가능.
TcpSocket
TCP연결이 수립될 수 있는지 체크함으로써 상태를 검사합니다.
• TCP연결이 생성될 수 없는 경우에 애플이케이션의 상태 검사가 실패한 것으로 간주합니다.
exec
컨테이너내부에서 명령어를 실행해 상태를 검사합니다. 명령어의 종료코드가0이 아닌 경우에 애플리케이션의 상태 검사가 실패한 것으로 간주합니다.
Pod restartPolicy 확인하기
# completed.yaml
cat > completed.yaml
apiVersion: v1
kind: Pod
metadata:
name: completed-pod
spec:
containers:
- name: completed-pod
image: busybox
command: ["sh"]
args: ["-c", "sleep 5 && exit 0"] #5초간 sleep 후 정상 종료 메시지를 날린다.
두 상태가 5초마다 바뀐다.



시작 -> 종료를 반복하다가 CrashLoopBackOff라는 상태가 발생한다.
상태가 바뀌고 있더라도, 멱등성에 의해 다시 만들어도 만들어지진 않는다.

이렇게 시작 -> 종료를 반복하는 이유를 restartPolicy를 확인해서 찾아보자.
k get pod completed-pod -o yaml | grep restartPolicy

restartPolicy를 확인해보면, 디폴트로 항상 다시 시작이 적용된다.
k apply -f completed.yaml && kubectl get pod -w
생성 명령어에 get pod -w 를 붙여서 생성의 실시간 정보를 볼 수 있다.
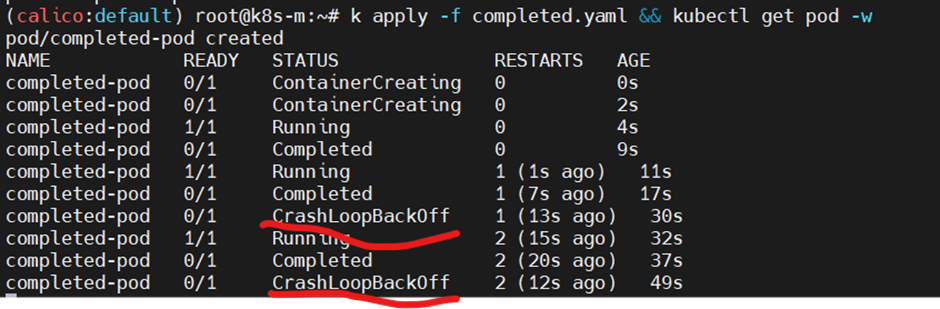
CrashLoopBackOff 상태
계속되는 재시작에 파드에 문제가 있다고 판단되어, 조금씩 재시작 텀을 길게 가져가도록 세팅된다.
즉, 이 상태는 재시작 까지 일정 시간 대기 중인 상태이다.
Pod restartPolicy 설정
# onfailure.yaml
apiVersion: v1
kind: Pod
metadata:
name: completed-pod
spec:
restartPolicy: OnFailure # 실패 시에만, 재시작
containers:
- name: completed-pod
image: busybox
command: ["sh"]
args: ["-c", "sleep 5 && exit 1"] #이번에는 0이아닌 값으로 종료해서 fail 시켜버림.

에러가 발생하면, 재시작 하게 된다.
이벤트 모니터링
watch -d "kubectl describe pod completed-pod | grep Events -A 12"
restartPolicy: OnFailure에서 정상 종료
cat << EOF | kubectl apply -f - && kubectl get pod -w
apiVersion: v1
kind: Pod
metadata:
name: completed-pod
spec:
restartPolicy: OnFailure #비정상 종료에만 재시작 시킴
containers:
- name: completed-pod
image: busybox
command: ["sh"]
args: ["-c", "sleep 5 && exit 0"] #정상 종료시킴
EOF
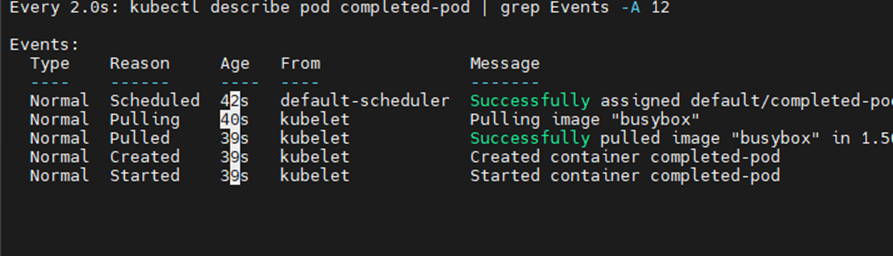
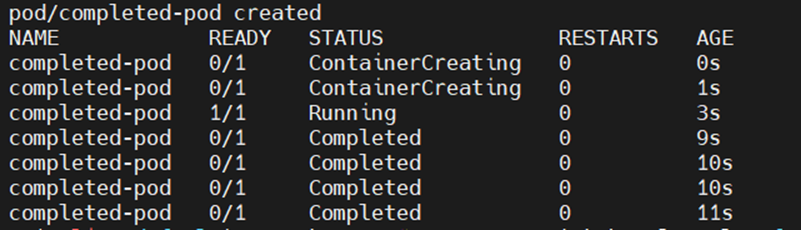
시작되고 5초후 종료된다.
restartPolicy: OnFailure이므로 재시작 되지 않고, 모든 명령어를 실행한 후 completed 상태에 돌입한다.
Liveness probe 동작 확인
#livenessprobe.yaml
apiVersion: v1
kind: Pod
metadata:
name: livenessprobe
spec:
containers:
- name: livenessprobe
image: nginx
livenessProbe: #리사이클 주기와 유사한 역할을 하게 됨.
httpGet:
port: 80 # 80번 포트로 http get요청을 계속 보내서 상태를 확인한다.
path: /index.html
k describe pod livenessprobe |grep Liveness

세팅을 확인해보면, 기본적으로 3번 실패 시 다시 재시작하는 세팅이다.

계속 모니터링 하자.
watch -d "kubectl logs livenessprobe -f"

10초 간격으로 kube-probe로부터 Get 요청이 오는 것이 확인된다.
이때 container의 index.html을 지워서 강제로 httpget을 fail 시키자.
k exec livenessprobe -- rm /usr/share/nginx/html/index.html # -- 명령어 실행
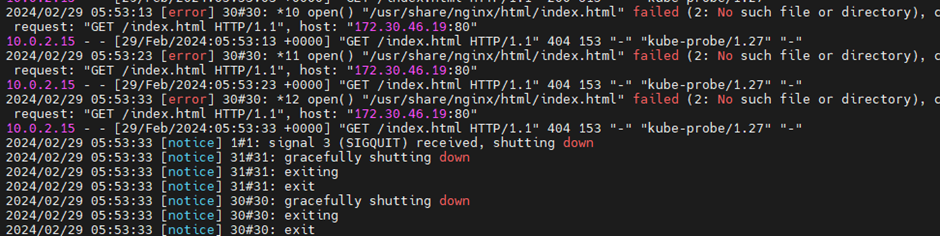
3번 fail된 것이 확인되어 restart 된다.
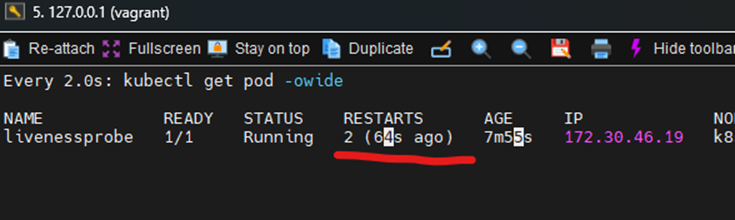
재시작되면 index가 다시 시작되는 image에는 남아있기 때문에 존재한다.

이후 probe가 계속 동작한다.
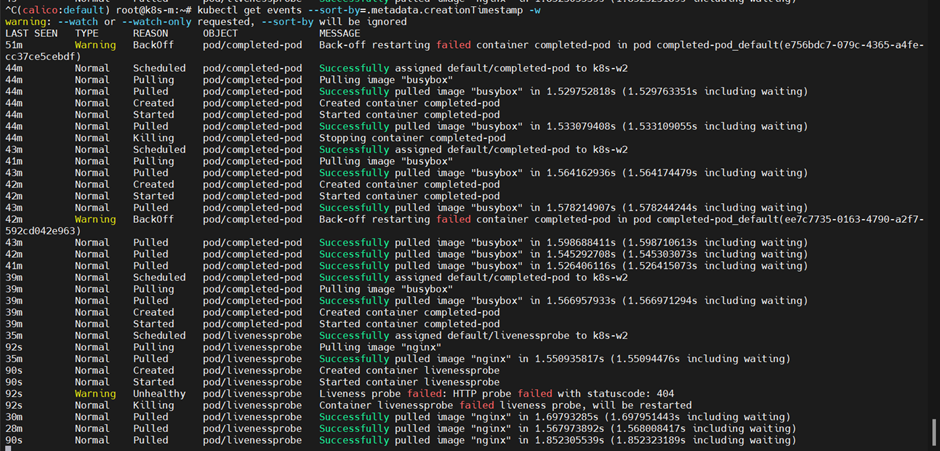
파드 생성 이벤트를 확인하면, Liveness Prove가 fail을 확인하고 재생성하는 것이 확인된다.
kubectl get events --sortby=.metadata.creationTimestamp -w
'CS > Kubernetes' 카테고리의 다른 글
| Kubernetes Deployment (업데이트, 롤백) (0) | 2024.03.04 |
|---|---|
| Kubernetes Replicasets 사용하기 (label) (0) | 2024.03.04 |
| Kubernetes Pod 활용하기 (Pause container, label, volume) (0) | 2024.03.03 |
| Kubernetes Kubectl 기본 명령어 정리 (0) | 2024.03.03 |
| Kubernetes Namespaces VS Linux Namespaces (Pause 컨테이너) (0) | 2024.03.03 |