
Go, Vantage point
가까운 곳을 걷지 않고 서는 먼 곳을 갈 수 없다.
Github | https://github.com/overnew/
Blog | https://everenew.tistory.com/
티스토리 뷰
다른 크롤러들과는 다르게 실제 user처럼 동작시키므로 원하는 데이터를 얻기 위해서는 일일이 조작시켜 주어야 한다.
이러한 방식은 귀찮지만, python의 request로 요청을 보내는 프로그램이 크롤링으로 감지되어 요청을 거절당한다면 사용할 수밖에 없는 대안이다.
설치하기
일단 공식 홈페이지에 들어가자.
selenium
pypi.org
최신 버전은 Python 3.7이상을 요구하고 있다.
- Python 3.7+
일단 pip 혹은 conda로 selenium을 설치해 주자.
pip install -U selenium
이제 크롬 드라이버를 버전에 맞게 설치해야 한다.
크롬의 설정에서 정보창에 버전을 확인해 주자.

크롬 드라이버 링크
https://chromedriver.chromium.org/downloads
ChromeDriver - WebDriver for Chrome - Downloads
Current Releases If you are using Chrome version 115 or newer, please consult the Chrome for Testing availability dashboard. This page provides convenient JSON endpoints for specific ChromeDriver version downloading. For older versions of Chrome, please se
chromedriver.chromium.org

그런데 현재 114 버전까지만 지원 중이라고 나온다.
붉은 글씨를 읽어보면 115 버전 이상은 직접 확인해 보라고 하는데
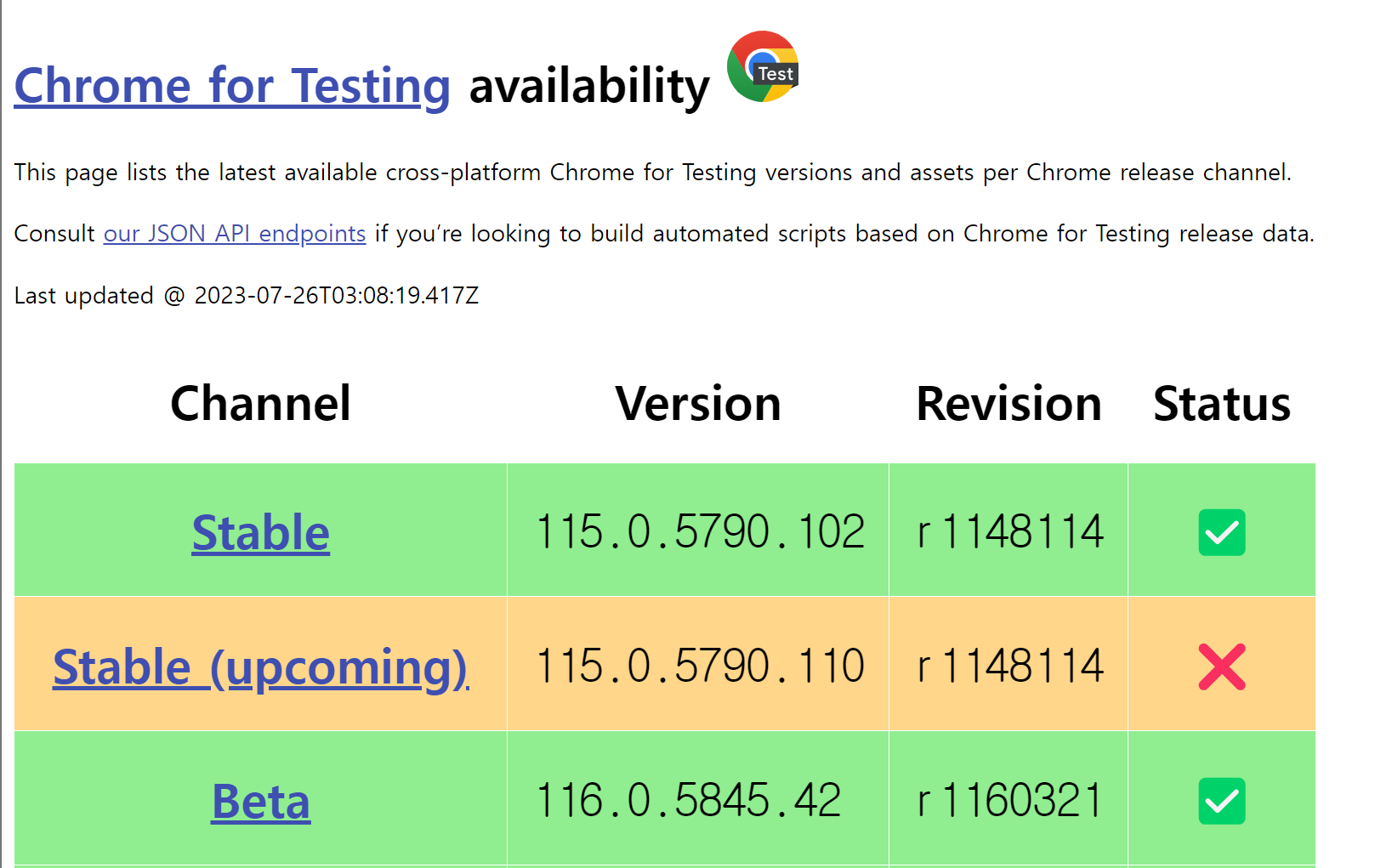
115.0.5790.102 버전은 지원되는 드라이버가 있다!
링크를 통해 받아주자.
크롤링하기
일단 공식 홈페이지의 예제 코드를 실행해 보자.
해당 코드를 돌리기 위해서는 다운로드한 chromedrive.exe를 같은 폴더 내에 넣어주어야 한다.

from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
browser = webdriver.Chrome()
browser.get('http://www.yahoo.com')
assert 'Yahoo' in browser.title
elem = browser.find_element(By.NAME, 'p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN)
browser.quit()
코드를 실행시키면 창이 자동으로 뜨게 된다.

야후 웹에서 search box를 찾고 selenium을 자동 기입하고 프로그램이 종료된다.
본인이 크롤링을 시도하려는 페이지는 사람인에서 it 직군 채용 정보이다.
일반적인 크롤링 방법으로는 요청이 거절당했으므로 selenium으로 시도하게 되었다.
페이지의 html코드를 확인해 보면 정보의 목록이 recruit_info_list의 class = "job_tit"에 담겨있는 것을 확인할 수 있다.


따라서 find_elements(by, name)을 사용해서 class = "job_tit"인 모든 element를 가져오자.
titles = browser.find_elements(By.CLASS_NAME, "job_tit")
class = "job_tit"의 text로 채용 정보의 제목을 가져올 수 있고, 하위 a태그에서는 정보의 링크가 있다.
따라서 하위 태그도 find_elements(by, name)를 통해 접근하면 데이터를 가져올 수 있다.
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('대상 url')
titles = browser.find_elements(By.CLASS_NAME, "job_tit"); # class로 가져오기
for i, tit in enumerate(titles):
print(tit.text)
body = tit.find_element(By.TAG_NAME, "a") # 태그로 가져오기
print(body.get_attribute("href"))
browser.implicitly_wait(3) #3초 대기 후 종료
browser.quit()
코드를 돌리면 아래와 같이 채용 정보를 파싱해 가져올 수 있다.

이외에도 클릭이나 텍스트 입력 등의 동작을 직접 코드를 작성해 실행할 수 있다.
크롤링 차단하는 방법이 발전할수록, 우회해서 크롤링하는 수단도 발전해나가고 있다...
'CS > 기타' 카테고리의 다른 글
| 왜 Web server와 WAS의 분리가 필요할까? (1) | 2024.07.14 |
|---|---|
| SQL과 데이터베이스 (0) | 2024.01.25 |
| [Github Actions] paths 로 폴더 별로 트리거 하기 (0) | 2023.11.18 |
| Slack bot으로 유저에게 1:1 DM 보내기 (0) | 2023.10.21 |
| [Linux] procfs, procseq 컴파일 에러 (error: variable '' has initializer but incomplete type) (0) | 2022.11.14 |