
Go, Vantage point
가까운 곳을 걷지 않고 서는 먼 곳을 갈 수 없다.
Github | https://github.com/overnew/
Blog | https://everenew.tistory.com/
티스토리 뷰
NVIDIA의 Geforce와 Quador 계열의 차이를 FP64, FP32 ,FP16, BF16들과 함께 알아보자.
Geforce(지포스)
일반적인 게이머들에게 가장 잘 알려진 개인용 컴퓨터 그래픽 칩셋으로 1999년부터 출시되었다.

Quadro(쿼드로)
Geforce와 동일하게 1999년도부터 출시한 전문가의 렌더링 작업용 그래픽 칩셋이다.
그럼에도 불구하고 칩셋은 Geforce와 동일한데, 소프트웨어적인 차이점이 있다.
FP32 vs FP64
두 계열의 차이를 알아보기 전에 FP32와 FP64의 차이를 알아보자.
FP(Floating Point Precision, 부동 소수점 정밀도)는 큰 범위 값을 정의하는 방식이다.
FP16은 반정밀도, FP32는 단정밀도, FP64는 배정밀도로 bit 개수가 더 클수록 더 자세한 소수점을 나타낼 수 있다.
FP32
FP32는 FP16에 비해 정밀도가 우수하고, FP64에 비해서는 크기가 작기 때문에 가장 많이 사용된다.
그만큼 FP64에 비해 정밀도는 떨어지지만 그만큼 메모리 소모가 적어 적절한 trade-off라고 볼 수 있다.
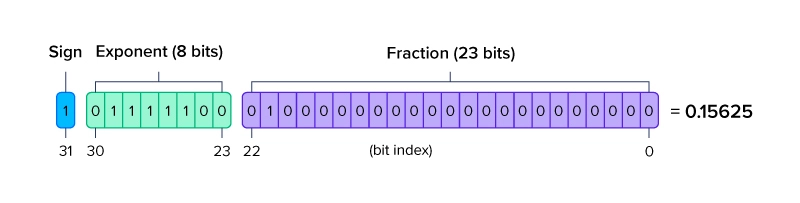
일반적으로 극한의 정밀도가 필요하지 않다면 대부분 사용할 수 있을 만큼 정확하고 빠르다.
따라서 머신러닝, 렌더링(게임)과 시뮬레이션 등에서 사용될 수 있다.
FP64
FP64는 FP32에 비해 구체적인 값을 계산하므로 시간이 오래 걸린다.
대신 그만큼 더 높은 정밀도가 필요한 워크로드에 특화되어 있다.
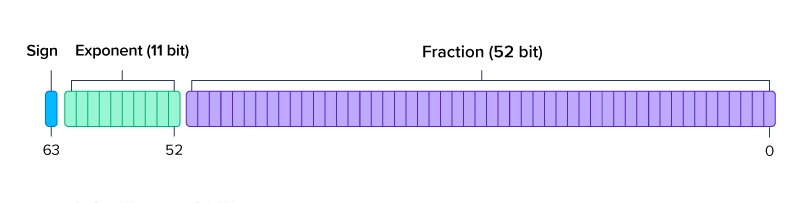
FP64를 머신러닝에 사용한다면 가중치를 곱하는 행렬곱셈의 크기와 시간이 급등하게 되어, 거의 사용되지 않는다.
FP64는 유체역학과 같은 높은 정밀도가 필요한 과학 계산에 사용된다.
또한 FP64 계산 유닛을 충분히 지원하는 GPU 또한 소수이다.(NVIDIA A100, NVIDIA H100 등)
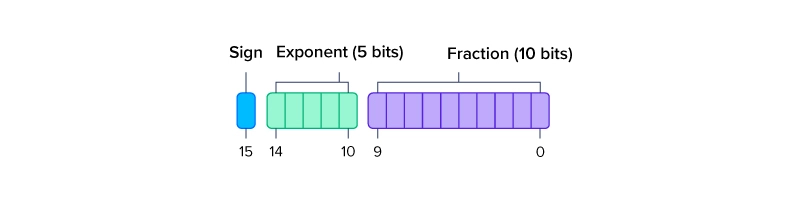
FP16
FP16은 표현 범위가 적은 만큼 정밀도가 낮다.
대신 가중치 곱이 중요하지 않는 신경망 모델에서는 빠른 속도를 제공할 수 있다.
BF16
BF16는 Google의 AI 연구 그룹인 Google Brain에서 개발한 형식이다.
FP16의 범위 제한은 딥러닝에 적합하지 않으므로 16bit는 크기는 지키고 FP32와 유사한 범위를 가지도록 세팅했다.
FP16에 비해 Exponent bit가 3개 늘리고 Fraction bot를 3개 줄였다.
따라서 FP32와 동일한 Exponent bit를 가지게 되어 비슷한 표현 범위를 가지지만, 정밀도는 더 줄어들게 되었다.
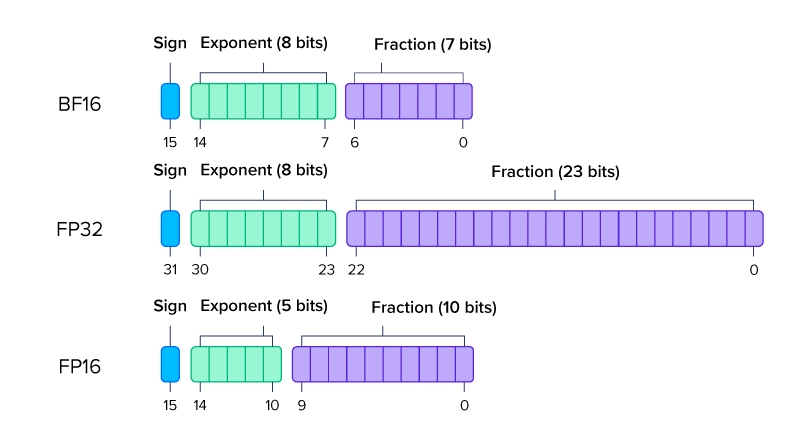
대신 FP32를 BF16으로 쉽게 변환할 수 있어 기존의 FP32를 사용한 모델들도 쉽게 대체할 수 있다.
따라서 대규모 학습 모델에서는 메모리가 적게 사용되는 16bit 표현 형식인 BF16이 사용된다.
단순히 계산하면 32bit로 표현된 값이 16bit로 줄게 되므로 50% 줄일 수 있다.
FP16의 경우 학습보다는 추론 분야에서 많이 사용된다.
결국에는 AI 모델 설계자가 정밀도와 시간 단축 간에 무엇을 선택할지 판단해야 한다.
Geforce VS Quadro
이제 본격적으로 Geforce와 Quadro를 비교해 보자.
기본적으로 동일한 CUDA core 수를 가진다면, Quadro 계열이 2배 이상 더 비싸다.
대신 Quadro 계열은 VRAM이 더 많이 제공된다.
게임
게이밍 성능 FP32 연산이 주를 이룬다. 따라서 동일가격 대비 CUDA core(계산 유닛)가 많은 Geforce 계열이 좋다.
2D 애플리케이션
포토샵과 같은 2D 애플리케이션은 CPU 성능에 의존한다고 한다.
단 블러, 초점 처리와 같은 작업이나 3D 작업에서는 GPU 기능이 사용된다.
이런 작업 또한 대부분 FP32 연산이기 때문에 CUDA core가 많은 Geforce가 유리하다.
3D 애플리케이션
캐드와 같은 3D 애플리케이션도 초정밀도 작업이 아니라면 FP32 연산이다.
따라서 Geforce가 추천된다.
FP64연산
초정밀도가 필요한 작업이라면 FP64 연산이 필요하다.
대부분의 NVIDIA GPU 제품은 FP64 계산을 지원하긴 하지만, FP64 계산에는 GPU가 FP64 연산 유닛이 제공되어야 빠른 계산이 가능하다.
FP64 유닛을 제공하는 대표적인 GPU가 NVIDIA A100, NVIDIA H100, NVIDIA A800, NVIDIA H200이다.
A100의 경우 FP32와 FP64의 비율은 2:1로 알려져 있다.
따라서 Geforce이냐 Quadro 이냐가 중요한 것이 아니라, GPU 제품의 FP64 유닛 수와 비율을 확인하여 결정해야 한다.
딥러닝
딥러닝도 결국 CUDA core 개수가 중요하다.
딥러닝에서는 FP32도 이용되지만, 대규모 학습이라면 BF16으로 메모리를 절약하여 구현하는 추세이다.
NVIDIA는 4x4 크기의 행렬 연산에 최적화된 Tensor Core를 개발해 RTX 카드에 사용한다.
따라서 딥러닝 또한 제품의 연산 속도를 보고 결정하자.
결론
살펴본 것처럼 컴퓨팅 니즈가 가격대비 CUDA Core의 개수가 중요한 상황이기 때문에,
대부분의 상황에서 Geforce 계열이 우위에 있다.
그러므로 Quadro는 더 많은 VRAM과 멀티 디스플레이 지원 등이 필요한 전문 그래픽 작업에서 이용되는 제품군이다.
GPU 제품 별로 다양한 스펙과 기능을 가지므로 계열 별로 비교하기 보다는 필요한 워크로드와 부합하는 GPU 제품을 선택하는 것이 옳을 것이다.
이미지 출처
FP64, FP32, FP16이란 무엇입니까? 부동 소수점 정의하기 | Exxact 블로그
추천 글
Quadro vs Geforce (쿼드로와 지포스의 차이) :: Steelblue
참조
Quadro vs Geforce (쿼드로와 지포스의 차이) :: Steelblue
FP64, FP32, FP16이란 무엇입니까? 부동 소수점 정의하기 | Exxact 블로그
[NVIDIA] CUDA Cores vs Tensor Cores
'CS > 하드웨어' 카테고리의 다른 글
| AI에 GPU가 필요한 이유와 CUDA에 대해서 (0) | 2025.03.07 |
|---|---|
| MIG와 vGPU의 차이 (GPU 가상화) (0) | 2025.03.06 |