
Go, Vantage point
가까운 곳을 걷지 않고 서는 먼 곳을 갈 수 없다.
Github | https://github.com/overnew/
Blog | https://everenew.tistory.com/
티스토리 뷰
이전글에서는 CUDA에 대해서 살펴보았다.
cuDNN이 무엇인지 알아보자.
cuDNN(CUDA Deep Neural Network)
cuDNN(CUDA Deep Neural Network)은 CUDA 프레임워크에서 딥러닝 가속화를 위한 라이브러리이다.

딥러닝에 많이 사용되는 Tensorflow, PyTorch, Keras와 같은 프레임워크에 활용되고 있다.
tensorflow의 특정 버전이 cuDNN과 CUDA의 특정 버전과 호환되는 것을 확인할 수 있다.

하지만 tensorflow에서 GPU 활용 코드를 작성할 때는 cuDNN 라이브러리를 직접 호출해서 사용하는 코드는 보이지 않는다.
## GPU의 메모리를 제한하는 tensorflow 코드 예시
gpus = tf.config.list_physical_devices('GPU')
if gpus:
# 텐서플로가 첫 번째 GPU에 1GB 메모리만 할당하도록 제한
try:
tf.config.set_logical_device_configuration(
gpus[0],
[tf.config.LogicalDeviceConfiguration(memory_limit=1024)])
except RuntimeError as e:
# 프로그램 시작시에 가상 장치가 설정되어야만 합니다
print(e)
즉 tensorflow의 내부 코드상에서 호출하는 것으로 구현되어 있으므로 모델 개발자는 cuDDN과 CUDA에 신경 쓸 필요 없이, tensorflow 코드 자체만 신경 쓰면 된다.
반대로 tensorflow 내부에서 호출하는 것이므로, 변경은 불가능하고 tensorflow와 cuDNN, CUDA의 버전은 반드시 호환되어야 한다.
이전의 개인 경험으로 개발된 후 몇년이 지난 과거의 tensorflow 모델 활용하려 하려면 CUDA의 7 버전을 사용해야 했다.
그런데 최신 GPU에서 지원하는 CUDA 버전이 해당 7버전 이하를 지원하지 않아, 결국 해당 모델을 사용하지 못하였다.
NVIDIA 이외의 벤더들의 GPU는 딥러닝 프레임워크를 어떻게 사용할까?
tensorflow는 CUDA를 통한 GPU 가속을 지원하고 있다.
그런데 CUDA는 NVIDIA의 GPU가 지원하는 프레임워크이다.
그렇다면 AMD의 GPU는 tensorflow와 같은 프레임워크를 사용할 수 없을까?
AMD GPU에서는 ROCm이라는 CUDA의 대체재를 제공한다.
Tensorflow에서도 ROCm을 지원하지만 오직 특정 버전에서만 지원된다.
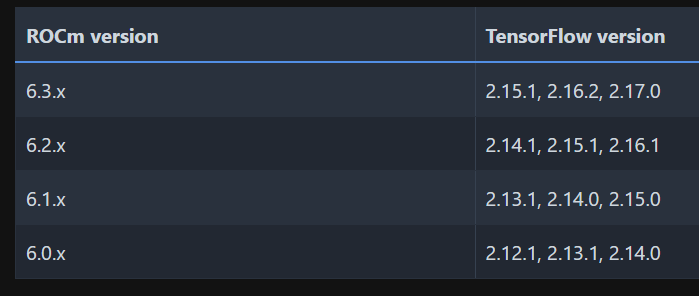
아무래도 NVIDIA에 비해 AMD는 후속 주자이기 때문에 많은 코드들이 CUDA로 작성되어 왔다.
따라서 호환성을 제공하기 위해 HIP API도 존재한다.
HIP(Heterogeneous-computing Interface for Portability) API
HIP API는 하나의 소스코드를 이기종 시스템(AMD or NVIDIA GPU)에서 동작 가능하도록 하는 C++ runtime API 그리고 kernel language이다.
HIP은 C++ 언어를 통해 AMD의 ROCm back-end와 NVIDIA의 CUDA back-end 응용 커널을 한 번에 빌드 및 실행할 수 있다.

공식 페이지에서는 HIP API는 AMD의 ROCm와 NVIDIA의 CUDA의 성능차이가 거의 없게 만들어 준다.
또한 각 환경에 맞는 성능 튜닝도 가능한다.
HIP은 HIPify와 HIPCC로 구성된다.
HIPify는 CUDA코드를 C++로 변환하는 역할을 담당하고
HIPCC는 C++ 코드를 AMD의 ROCm나 NVIDIA의 CUDA 환경에서 동작 가능하게 컴파일해 준다.

AMD의 설명만 들어보면 완벽히 대체 가능해 보이지만, 조사를 해보니 ML 시장에서 AMD는 여전히 인기 있진 않다.
아무리 이식가능한 HIP가 있다고 해도 기본적으로 NVidia와 AMD GPU의 설계가 다르고 최적화에 차이점이 있기 때문에,
CUDA의 코드가 완벽한 성능으로 이식되긴 힘들다.
참조
Radeon의 숨겨진 힘, ROCm 으로 깨워보자! > 배틀리뷰 - 하드웨어 배틀(Hardware Battle)
[D] CUDA가 ROCm보다 훨씬 빠른 이유는 무엇입니까? : r/머신러닝
What is HIP? — HIP 6.4.0 Documentation
[DL] CUDA, cuDNN이란? - layered architecture for Deep Learning
CUDA Deep Neural Network (cuDNN) | NVIDIA Developer
'CS > GNN' 카테고리의 다른 글
| [논문 리뷰] Light Graph Convolutional Collaborative FilteringWith Multi-Aspect Information (0) | 2023.03.08 |
|---|---|
| Attention 간단 정리 (0) | 2023.02.23 |
| Seq2Seq 간단 정리 (0) | 2023.02.23 |
| [논문 리뷰] LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation (0) | 2023.01.05 |
| [GNN] Graph Neural Network - 2 (0) | 2023.01.04 |